Biologie I

Abbildung 1. Ein Nukleotid besteht aus drei Komponenten: einer stickstoffhaltigen Base, einem Pentosezucker und einer oder mehreren Phosphatgruppen. Die Kohlenstoffreste in der Pentose sind mit 1′ bis 5′ nummeriert (die Primzahl unterscheidet diese Reste von denen in der Base, die ohne Primzahlschreibweise nummeriert sind). Die Base ist an die 1′-Position der Ribose gebunden, das Phosphat an die 5′-Position. Wenn ein Polynukleotid gebildet wird, bindet das 5′-Phosphat des ankommenden Nukleotids an die 3′-Hydroxylgruppe am Ende der wachsenden Kette. Es gibt zwei Arten von Pentose in Nukleotiden, Desoxyribose (in der DNA) und Ribose (in der RNA). Die Desoxyribose ist in ihrer Struktur der Ribose ähnlich, hat aber ein H statt eines OH an der 2′-Position. Basen können in zwei Kategorien unterteilt werden: Purine und Pyrimidine. Purine haben eine doppelte Ringstruktur und Pyrimidine haben einen einzelnen Ring.
Die stickstoffhaltigen Basen, wichtige Bestandteile der Nukleotide, sind organische Moleküle und heißen so, weil sie Kohlenstoff und Stickstoff enthalten. Sie sind Basen, weil sie eine Aminogruppe enthalten, die das Potenzial hat, einen zusätzlichen Wasserstoff zu binden, und somit die Wasserstoffionenkonzentration in ihrer Umgebung verringert, was sie basischer macht. Jedes Nukleotid in der DNA enthält eine von vier möglichen stickstoffhaltigen Basen: Adenin (A), Guanin (G), Cytosin (C) und Thymin (T). RNA-Nukleotide enthalten ebenfalls eine von vier möglichen Basen: Adenin, Guanin, Cytosin und Uracil (U) anstelle von Thymin.
Adenin und Guanin werden als Purine klassifiziert. Die Primärstruktur eines Purins sind zwei Kohlenstoff-Stickstoff-Ringe. Cytosin, Thymin und Uracil werden als Pyrimidine klassifiziert, die einen einzigen Kohlenstoff-Stickstoff-Ring als Primärstruktur haben (Abbildung 1). Jeder dieser grundlegenden Kohlenstoff-Stickstoff-Ringe hat verschiedene funktionelle Gruppen, die an ihn gebunden sind. In der molekularbiologischen Kurzschrift sind die stickstoffhaltigen Basen einfach unter den Symbolen A, T, G, C und U bekannt. Die DNA enthält A, T, G und C, während die RNA A, U, G und C enthält.
Der Pentosezucker in der DNA ist die Desoxyribose, und in der RNA ist der Zucker die Ribose (Abbildung 1). Der Unterschied zwischen den Zuckern ist das Vorhandensein der Hydroxylgruppe am zweiten Kohlenstoff der Ribose und des Wasserstoffs am zweiten Kohlenstoff der Desoxyribose. Die Kohlenstoffatome des Zuckermoleküls sind mit 1′, 2′, 3′, 4′ und 5′ nummeriert (1′ wird als „eine Primzahl“ gelesen). Der Phosphatrest ist an die Hydroxylgruppe des 5′-Kohlenstoffs des einen Zuckers und die Hydroxylgruppe des 3′-Kohlenstoffs des Zuckers des nächsten Nukleotids gebunden, wodurch eine 5′-3′-Phosphodiesterbindung entsteht. Die Phosphodiester-Bindung wird nicht durch eine einfache Dehydratisierungsreaktion gebildet wie die anderen Bindungen, die Monomere in Makromolekülen verbinden: Ihre Bildung beinhaltet die Entfernung von zwei Phosphatgruppen. Ein Polynukleotid kann Tausende solcher Phosphodiesterbindungen aufweisen.
DNA-Doppelhelixstruktur
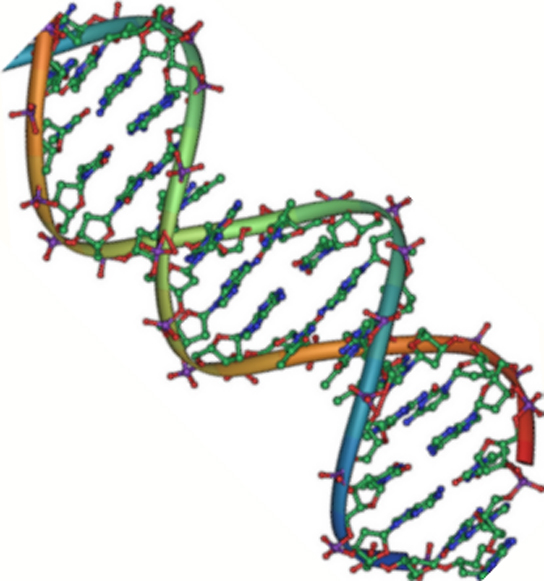
Abbildung 2. Die DNA ist eine antiparallele Doppelhelix. Das Phosphatgerüst (die geschwungenen Linien) befindet sich auf der Außenseite, und die Basen sind auf der Innenseite. Jede Base interagiert mit einer Base des gegenüberliegenden Strangs. (credit: Jerome Walker/Dennis Myts)
DNA hat eine Doppelhelixstruktur (Abbildung 2). Der Zucker und das Phosphat liegen an der Außenseite der Helix und bilden das Rückgrat der DNA. Die stickstoffhaltigen Basen sind im Inneren, wie die Stufen einer Treppe, paarweise gestapelt; die Paare sind durch Wasserstoffbrückenbindungen miteinander verbunden. Jedes Basenpaar in der Doppelhelix ist vom nächsten Basenpaar durch 0,34 nm getrennt.
Die beiden Stränge der Helix verlaufen in entgegengesetzter Richtung, d. h. das 5′-Kohlenstoff-Ende des einen Stranges steht dem 3′-Kohlenstoff-Ende des Gegenstranges gegenüber. (Dies wird als antiparallele Orientierung bezeichnet und ist wichtig für die DNA-Replikation und für viele Nukleinsäure-Interaktionen)
Nur bestimmte Arten der Basenpaarung sind erlaubt. Zum Beispiel kann sich ein bestimmtes Purin nur mit einem bestimmten Pyrimidin paaren. Das bedeutet, dass sich A mit T und G mit C paaren kann, wie in Abbildung 3 dargestellt. Dies ist als Basenkomplementärregel bekannt. Mit anderen Worten: Die DNA-Stränge sind komplementär zueinander. Wenn die Sequenz des einen Strangs AATTGGCC ist, würde der komplementäre Strang die Sequenz TTAACCGG haben. Während der DNA-Replikation wird jeder Strang kopiert, was zu einer Tochter-DNA-Doppelhelix führt, die einen elterlichen DNA-Strang und einen neu synthetisierten Strang enthält.
Praxis
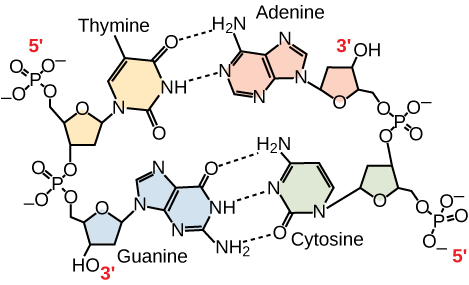
Abbildung 3. In einem doppelsträngigen DNA-Molekül verlaufen die beiden Stränge antiparallel zueinander, so dass ein Strang 5′ zu 3′ und der andere 3′ zu 5′ verläuft. Das Phosphatgerüst befindet sich außen und die Basen in der Mitte. Adenin bildet Wasserstoffbrücken (oder Basenpaare) mit Thymin, und Guanin bildet Basenpaare mit Cytosin.
Eine Mutation tritt auf, und Cytosin wird durch Adenin ersetzt. Welche Auswirkungen wird dies Ihrer Meinung nach auf die DNA-Struktur haben?
RNA
Ribonukleinsäure, oder RNA, ist hauptsächlich am Prozess der Proteinsynthese unter der Leitung der DNA beteiligt. RNA ist in der Regel einzelsträngig und besteht aus Ribonukleotiden, die durch Phosphodiesterbindungen verbunden sind. Ein Ribonukleotid in der RNA-Kette enthält Ribose (den Pentosezucker), eine der vier stickstoffhaltigen Basen (A, U, G und C) und die Phosphatgruppe.
Es gibt vier Haupttypen von RNA: Boten-RNA (mRNA), ribosomale RNA (rRNA), Transfer-RNA (tRNA) und microRNA (miRNA). Die erste, die mRNA, transportiert die Botschaft der DNA, die alle zellulären Aktivitäten in einer Zelle steuert. Wenn eine Zelle die Synthese eines bestimmten Proteins benötigt, wird das Gen für dieses Produkt „angeschaltet“ und die Boten-RNA wird im Zellkern synthetisiert. Die Basensequenz der RNA ist komplementär zu der kodierenden Sequenz der DNA, von der sie abgeschrieben wurde. Allerdings fehlt in der RNA die Base T und stattdessen ist U vorhanden. Wenn der DNA-Strang die Sequenz AATTGCGC hat, ist die Sequenz der komplementären RNA UUAACGCG. Im Zytoplasma interagiert die mRNA mit Ribosomen und anderen zellulären Maschinen (Abbildung 4).
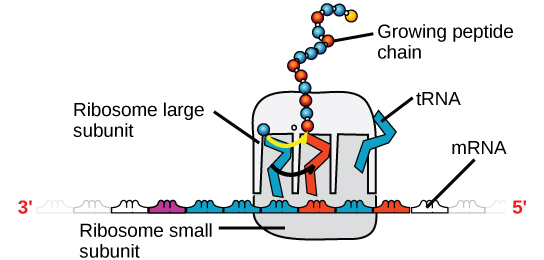
Abbildung 4. Ein Ribosom hat zwei Teile: eine große Untereinheit und eine kleine Untereinheit. Die mRNA befindet sich zwischen den beiden Untereinheiten. Ein tRNA-Molekül erkennt ein Codon auf der mRNA, bindet daran durch komplementäre Basenpaarung und fügt die richtige Aminosäure an die wachsende Peptidkette an.
Die mRNA wird in Sätzen von drei Basen gelesen, die als Codons bezeichnet werden. Jedes Codon kodiert für eine einzelne Aminosäure. Auf diese Weise wird die mRNA abgelesen und das Proteinprodukt hergestellt. Die ribosomale RNA (rRNA) ist ein Hauptbestandteil der Ribosomen, an die sich die mRNA bindet. Die rRNA sorgt für die richtige Ausrichtung der mRNA und der Ribosomen; die rRNA des Ribosoms hat auch eine enzymatische Aktivität (Peptidyltransferase) und katalysiert die Bildung der Peptidbindungen zwischen zwei ausgerichteten Aminosäuren. Die Transfer-RNA (tRNA) ist eine der kleinsten der vier RNA-Typen, normalerweise 70-90 Nukleotide lang. Sie transportiert die richtige Aminosäure zum Ort der Proteinsynthese. Es ist die Basenpaarung zwischen der tRNA und der mRNA, die es ermöglicht, dass die richtige Aminosäure in die Polypeptidkette eingefügt wird. microRNAs sind die kleinsten RNA-Moleküle und ihre Rolle beinhaltet die Regulierung der Genexpression, indem sie die Expression bestimmter mRNA-Botschaften stören.