La Gema Oculta de SQL Server: UPDATE from SELECT
3 formas sencillas de utilizar UPDATE from SELECT facilitando tu trabajo
Probablemente te hayas encontrado alguna vez en esta situación: Has necesitado actualizar los datos de una tabla utilizando la información almacenada en otra tabla. A menudo me encuentro con personas que no han oído hablar de la potente solución UPDATE from SELECT que ofrece SQL Server para este problema. De hecho, yo luché con este problema durante bastante tiempo antes de conocer esta joya.
En las siguientes líneas, voy a mostraros tres trucos que me han simplificado la vida en muchas ocasiones. Para ello, primero necesitamos dos tablas:

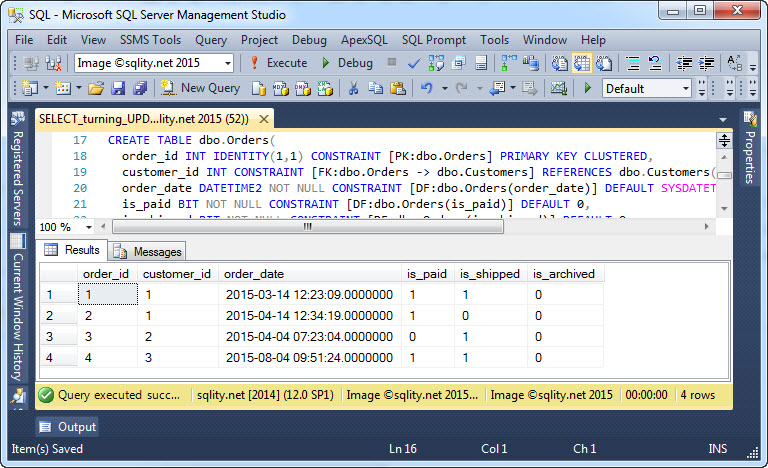
Si quieres seguir, puedes conseguir el script aquí: La Gema Oculta de SQL Server – UPDATE desde SELECT.sql
Desarrolla tu UPDATE desde un SELECT
Ahora que tenemos el entorno configurado, vamos a sumergirnos en cómo hacer que esto funcione. Antes de mostrarte la solución multi-tabla, permíteme demostrar la forma más simple de la sintaxis UPDATE FROM y mostrarte un sencillo truco para hacer que el desarrollo de tus sentencias UPDATE sea realmente simple, escribiendo primero una sentencia SELECT y luego convirtiéndola en una actualización borrando dos caracteres. ¿Intrigado?
La tabla dbo.Orders contiene una columna is_archived. Esta se utiliza para archivar los pedidos de más de 90 días. Sin embargo, tenemos la regla adicional de que los pedidos que aún no han sido pagados o enviados no pueden ser archivados. (En este ejemplo, la columna is_archived no tiene ningún efecto físico. Consulte mi artículo de SQL Server Pro Using Table Partitions to Archive Old Data in OLTP Environments (Uso de particiones de tabla para archivar datos antiguos en entornos OLTP) si le interesa saber cómo convertir la columna is_archived en un interruptor de archivo real.)
Una sentencia SELECT para devolver los registros archivables tendría este aspecto:
FROM dbo.Orders AS O
WHERE O.order_date < DATEADD(DAY,-90,SYSDATETIME())
AND O.is_paid = 1
AND O.is_shipped = 1;
Ahora vamos a añadirle un poco de magia:
SELECT *, — */
is_archived = 1
FROM dbo.Orders AS O
WHERE O.order_date < DATEADD(DAY,-90,SYSDATETIME())
AND O.is_paid = 1
AND O.is_shipped = 1;
Esto sigue siendo una simple sentencia SELECT. Sólo hemos añadido dos comentarios y una columna adicional. Esa columna adicional está utilizando la sintaxis poco común de alias nombre = valor con es equivalente a la sintaxis más común valor COMO nombre.
La belleza de esto radica en el hecho de que puedo convertir esta selección en una sentencia UPDATE sintácticamente correcta, simplemente eliminando los dos guiones delante de la palabra clave UPDATE:
SELECT *, — */
is_archived = 1
FROM dbo.Orders AS O
WHERE O.order_date < DATEADD(DAY,-90,SYSDATETIME())
AND O.is_paid = 1
AND O.is_shipped = 1;
Esto actualiza la tabla dbo.Orders igual que lo haría una sentencia UPDATE dbo.Orders SET…, porque la tabla dbo.Orders tiene el alias O y el UPDATE hace referencia a ese mismo alias O.
Añadir un JOIN a la sentencia UPDATE
La pregunta que nos hizo aquí fue cómo podemos utilizar los datos de una tabla para actualizar otra tabla. No sería bueno que pudiéramos simplemente hacer un «JOIN»? Buenas noticias: La sintaxis anterior nos permite hacer precisamente eso.
Recientemente se añadió una columna order_count a la tabla dbo.Customers. Nuestro trabajo ahora es valorar correctamente esa columna en función de los pedidos reales que ha realizado cada cliente. Empezamos de nuevo escribiendo un select primero:
SELECT *, — */
order_count = OA.cnt
FROM dbo.Customers AS C
JOIN(
SELECT O.customer_id,
COUNT(1) cnt
FROM dbo.Orders AS O
GROUP BY O.customer_id
)OA
ON C.customer_id = OA.customer_id;
Una vez que la sentencia SELECT devuelve los resultados correctos, es fácil cambiarla a UPDATE:
SELECT *, — */
order_count = OA.cnt
FROM dbo.Customers AS C
JOIN(
SELECT O.customer_id,
COUNT(1) cnt
FROM dbo.Orders AS O
GROUP BY O.customer_id
)OA
ON C.customer_id = OA.customer_id;
Debido al uso del alias C, SQL Server sabe que debe actualizar la tabla dbo.Customers mientras extrae la información necesaria de otra(s) tabla(s) referenciada(s) en la sentencia.
Usando UPDATE con un CTE
Si los CTEs son lo tuyo, puedes incluso ir un paso más allá con esto. Siempre que SQL Server pueda determinar fácilmente lo que se pretende actualizar, se puede realmente «UPDATE» un CTE directamente utilizando una sintaxis muy similar:
(
SELECT O.customer_id,
COUNT(1) cnt
FROM dbo.Orders AS O
GROUP BY O.customer_id
),
customer_order_counts AS
(
SELECT
C.customer_id,
C.name,
C.order_count,
OC.cnt new_order_cnt
FROM dbo.Customers AS C
JOIN order_counts AS OC
ON C.customer_id = OC.customer_id
)
UPDATE COC SET /*
SELECT *, — */
order_count = COC.new_order_cnt
FROM customer_order_counts AS COC;
Lo único que no se puede hacer con ninguna de las sentencias anteriores, es actualizar datos en dos tablas al mismo tiempo.
Una palabra de precaución
Esta sintaxis nos proporciona una forma muy potente de escribir sentencias UPDATE que requieren datos de más de una tabla. Sin embargo, tenga cuidado de no escribir código que muestre un comportamiento aleatorio. Echa un vistazo a esta sentencia UPDATE:
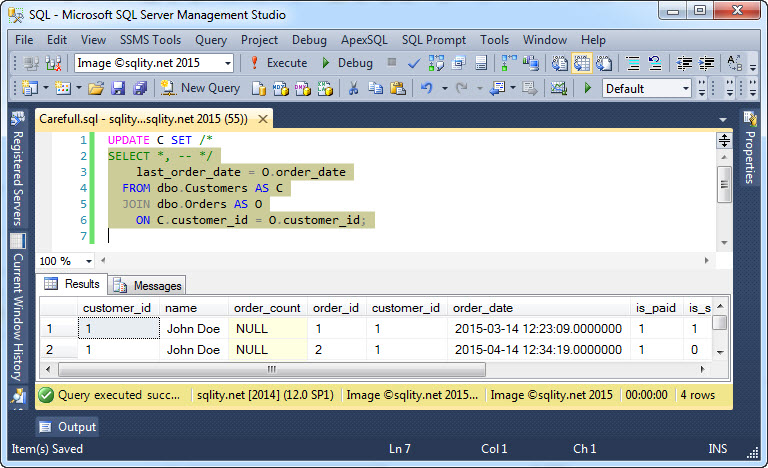
Al igual que el SELECT resaltado devuelve un cliente con múltiples pedidos varias veces, el UPDATE actualizaría alegremente cada cliente varias veces, sobrescribiendo cada vez el cambio anterior. Sólo el último cambio persistiría.
El problema con eso es que no hay garantía de en qué orden sucede eso. El orden depende del plan de ejecución elegido y puede cambiar en cualquier momento. Así que mientras la declaración anterior podría realmente resultar en la última fecha de orden que se escribe en sus pruebas, es probable que se ejecute en un orden diferente una vez que la declaración se encuentra con una gran cantidad de datos. Esto conducirá a problemas difíciles de depurar, así que preste atención a esta posibilidad, cuando escriba sus sentencias UPDATE FROM SELECT.