SQLShack
Los desarrolladores de bases de datos a menudo necesitan convertir un valor separado por comas u otros elementos delimitados a un formato tabular. Los delimitadores incluyen la tubería «|», la almohadilla «#», el dólar «$» y otros caracteres. El nivel de compatibilidad 130 de SQL Server, y las versiones posteriores, admiten una función string_split() para convertir los valores separados por delimitadores en filas (formato de tabla). Para los niveles de compatibilidad inferiores a 130, los desarrolladores han hecho esto previamente con una función definida por el usuario, que incorpora un bucle While o Cursor para extraer los datos.
¿Por qué se requiere la entrada separada por comas para un procedimiento o consulta T-SQL?
Ejecutar un programa en una iteración utilizando un bucle es un método común en la aplicación de back-end, así como en la base de datos. Cuando el recuento de iteraciones es menor de lo esperado, el tiempo de ejecución puede ser menor sin embargo el número de iteraciones es mayor lo que lleva a un mayor tiempo de procesamiento. Por ejemplo, si la aplicación está obteniendo datos de una base de datos con la ejecución de un trozo de programa en un bucle analizando diferentes parámetros de entrada, la aplicación tendrá que envolver la respuesta de la base de datos de cada iteración. Para manejar este tipo de situación, podemos ejecutar el mismo programa con una sola ejecución con el análisis de los valores separados por comas o delimitadores como un parámetro de entrada en la base de datos y convertirlo en formato tabular en el programa T-SQL para proceder con la lógica posterior.
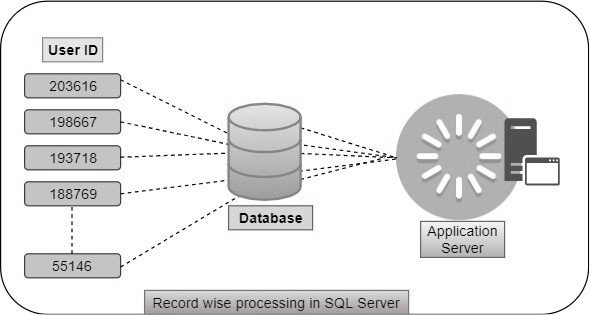
Hoy en día, muchas plataformas han cambiado a la arquitectura de micro-servicio. No sólo la aplicación, sino también el diseño de la base de datos podría estructurarse en una arquitectura basada en micro-servicios y la mayor parte de la comunicación interna entre las bases de datos se realiza con referencias enteras solamente. Esa es la razón para conseguir alguna forma complicada de lograr una mejor ejecución desde el lado de la base de datos.
Múltiples entradas al mismo parámetro se pueden lograr con valores separados por comas en el parámetro de entrada del procedimiento almacenado o la entrada a la función tabular, y se utiliza con la tabla en una sentencia T-SQL. Puede haber más situaciones para esta estrategia cuando se utiliza T-SQL. Al programar con SQL Server, un desarrollador debe dividir una cadena en elementos utilizando un separador. Usando la función de división contra la cadena define el separador como un parámetro de entrada. La cadena completa será dividida y devuelta como una tabla. En determinadas circunstancias, el parámetro de entrada puede ser una combinación de dos o más valores separados por caracteres para cada conjunto de entrada. Por ejemplo:
N’203616, 198667, 193718, 188769,…’ N’1021|203616$1021|198667$1022|193718$1022|188769$…’ N’1021|203616,198667$1022|193718,188769$…’
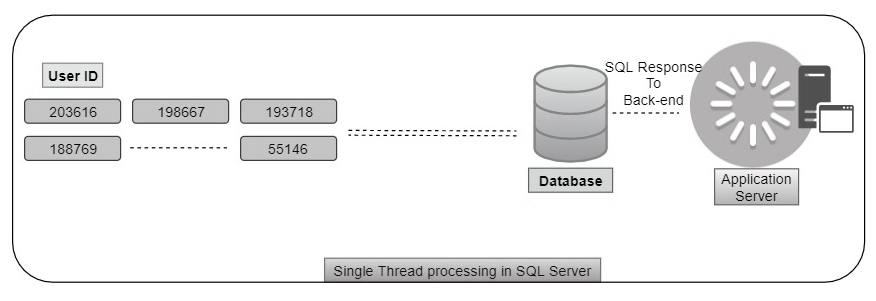
La ejecución de un solo hilo con valores separados por comas tiene ventajas sobre la ejecución de varios hilos en SQL Server:
- Ejecución única para una parte del programa, lo que redunda en el número de entradas
- Una sola operación de lectura o escritura sobre las tablas de la base de datos en lugar de varias iteraciones utilizando un bucle
- Uso único de activos del servidor
- No hay más obstáculos en la aplicación de back-end para configurar una respuesta a partir de múltiples conjuntos de resultados
- Un commit de una sola vez significa que la base de datos/SQL Server no bloqueará la transacción y ralentizará las cosas. Por lo tanto, no hay posibilidades de bloqueo
- Fácil de supervisar la consistencia de la transacción
- Autor
- Postes recientes
- Page Life Expectancy (PLE) in SQL Server – July 17, 2020
- Cómo automatizar el particionamiento de tablas en SQL Server – 7 de julio de 2020
- Cómo configurar los grupos de disponibilidad Always On de SQL Server en AWS EC2 – 6 de julio de 2020
- Author
- Recent Posts
- Page Life Expectancy (PLE) in SQL Server – July 17, 2020
- How to automate Table Partitioning in SQL Server – July 7, 2020
- Configuring SQL Server Always On Availability Groups on AWS EC2 – July 6, 2020
- Author
- Recent Posts
- Page Life Expectancy (PLE) in SQL Server – July 17, 2020
- How to automate Table Partitioning in SQL Server – July 7, 2020
- Configuring SQL Server Always On Availability Groups on AWS EC2 – July 6, 2020
- Author
- Recent Posts
- Page Life Expectancy (PLE) in SQL Server – July 17, 2020
- How to automate Table Partitioning in SQL Server – July 7, 2020
- Configuring SQL Server Always On Availability Groups on AWS EC2 – July 6, 2020
Función de división usando bucle
En la mayoría de los casos, un desarrollador escribe la función de valores de tabla con un bucle para extraer los datos de valores separados por comas a una lista o formato de tabla. Un bucle extrae la tupla una a una con la recursión. Los problemas de rendimiento pueden surgir cuando se trabaja con el parámetro de entrada grande, ya que tomará más tiempo para extraerlo. Aquí, tenemos una función simple con el nombre de split_string, que está utilizando un bucle dentro de la función de valor de tabla. Esta función permite dos argumentos o parámetros de entrada (1 – cadena de entrada y 2 – delimitador):
|
1
2
.. 3
4
. 5
6
7
8
9
10
11
12
13
14
15
16
17
|
CREATE FUNCTION split_string
(
@in_string VARCHAR(MAX),
@delimitación VARCHAR(1)
)
Retorna @lista TABLA(tupla VARCHAR(100))
Como
Empezar
WHILE LEN(@in_string) > 0
Empezar
INSERT INTO @list(tupla)
SELECT left(@in_string, charindex(@delimitador, @in_cadena+’,’) -1) como tupla
SET @in_cadena = stuff(@in_cadena, 1, charindex(@delimitador, @in_cadena + @delimitador), »)
end
RETURN
END
|
Una tabla de conjunto de resultados devuelta por esta función contiene cada subcadena de la cadena del parámetro de entrada que está separada por el delimitador. Las subcadenas de la tabla están en el orden en que se producen en el parámetro de entrada. Si el separador o delimitador no coincide con ningún trozo de la cadena de entrada, la tabla de salida tendrá un solo componente. La función tabular devolverá el conjunto de resultados en formato fila-columna de la cadena separada por comas.
|
1
|
SELECT * FROM split_string(‘1001,1002,1003,1004’, ‘,’)
|
Las versiones recientes de SQL Server proporcionan una función incorporada string_split() para realizar la misma tarea con los parámetros de entrada de la cadena de entrada y el delimitador. Pero hay otra forma eficiente de realizar esta tarea utilizando XML.
Función Split utilizando XML
La función Split utilizando la lógica XML es un método útil para separar valores de una cadena delimitada. El uso de la lógica XML con el enfoque XQUERY basado en T-SQL hace que el T-SQL no se caracterice como una recursividad utilizando un bucle o un cursor. Esencialmente, la cadena de parámetros de entrada se convierte en XML sustituyendo el nodo XML en la articulación T-SQL. El XML resultante se utiliza en XQUERY para extraer el valor del nodo en el formato de tabla. También resulta en un mejor rendimiento.
Por ejemplo, tenemos un valor separado por comas con la variable @user_ids en la siguiente declaración T-SQL. En una variable, se sustituye la coma por las etiquetas XML para convertirla en un documento de tipo de datos XML y luego se extrae utilizando XQUERY con el XPATH como ‘/root/U’:
|
1
2
3
4
5
6
7
8
9
10
|
DECLARE @user_ids NVARCHAR(MAX) = N’203616, 198667, 193718, 188769, 183820, 178871, 173922, 168973, 164024, 159075, 154126, 149177, 144228, 139279, 134330, 129381, 124432, 119483, 114534, 109585, 104636, 99687, 94738, 89789, 84840, 79891, 74942, 69993, 65044, 60095, 55146′
DECLARE @sql_xml XML = Cast(‘<root><U>’+ Replace(@user_ids, ‘,’, ‘</U><U></U></root>’ AS XML)
SELECT f.x.value(‘.’, ‘BIGINT’) AS user_id
INTO #users
FROM @sql_xml.nodes(‘/root/U’) f(x)
SELECT *
FROM #users
|

En la función anterior, hemos utilizado el tipo de datos VARCHAR (100) para el valor extraído en lugar de BIGINT. También puede haber cambios en la cadena de parámetros de entrada. Por ejemplo, si la cadena de entrada tiene un ‘,’ extra al principio o al final de la cadena, devuelve una fila extra con 0 para el tipo de datos BIGINT y » para VARCHAR.
Por ejemplo,
|
1
2
3
4
5
|
DECLARE @user_ids VARCHAR(MAX) = N’203616, 198667, 193718, 188769, 183820, 178871,’
DECLARE @sql_xml XML = Cast(‘<root><U>’+ Replace(@user_ids, ‘,’, ‘</U><U></U></root>’ AS XML)
SELECT f.x.value(‘.’, ‘BIGINT’) AS user_id
FROM @sql_xml.nodes(‘/root/U’) f(x)
|

Para manejar este tipo de datos » o 0 en el conjunto de resultados, podemos añadir la condición siguiente en la sentencia T-SQL:
|
1
2
3
4
5
6
|
DECLARE @user_ids VARCHAR(MAX) = N’203616, 198667, 193718, 188769, 183820, 178871,’
DECLARE @sql_xml XML = Cast(‘<root><U>’+ Replace(@user_ids, ‘,’, ‘</U><U></U></root>’ AS XML)
SELECT f.x.value(‘.’, ‘BIGINT’) AS user_id
FROM @sql_xml.nodes(‘/root/U’) f(x)
WHERE f.x.value(‘.’, ‘BIGINT’) <> 0
|
Aquí, f.x.value(‘.’, ‘BIGINT’) <> 0 excluye el 0 y f.x.value(‘.’, ‘VARCHAR(100)’) <> » en el conjunto de resultados de la consulta. Esta condición T-SQL se puede añadir en las funciones con valores de tabla con el número de parámetro de entrada para manejar este delimitador extra.
Función:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
CREATE FUNCTION split_string_XML
(
@in_string VARCHAR(MAX),
@delimitación VARCHAR(1)
)
Retorna @lista TABLA(tupla VARCHAR(100))
Como
Empezar
DECLARE @sql_xml XML = Cast(‘<root><U>’+ Replace(@in_string, @delímetro, ‘</U><U></U></root>’ AS XML)
INSERT INTO @list(tuple)
SELECT f.x.value(‘.’, ‘VARCHAR(100)’) AS tuple
FROM @sql_xml.nodes(‘/root/U’) f(x)
WHERE f.x.value(‘.’, ‘BIGINT’) <> 0
RETURN
END
|
Ejecución:
|
1
2
SELECT *
FROM split_string_XML(‘203616,198667,193718,188769,183820,178871,173922,’, ‘,’)
|
Combinación de caracteres en cadena separada por delimitadores
¿Pero qué ocurre cuando el parámetro de entrada es una combinación de dos valores con múltiples separadores? En este caso, el parámetro de entrada debe extraerse dos veces con la ayuda de una subconsulta, como se muestra a continuación:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
DECLARE @in_string VARCHAR(MAX) = ‘1021|203616$1021|198667$1022|193718$1022|188769 XML = Cast(‘<root><U>’+ Replace(@in_string, ‘ ‘</U><U></U></root>’ AS XML)
SELECT X.Y.value(‘(U)’, ‘VARCHAR(20)’) AS role_id,
X.Y.value(‘(U)’, ‘VARCHAR(20)’) AS user_id
FROM
(
SELECT Cast(‘<root><U>’+ Replace(f.x.value(‘.’, ‘VARCHAR(MAX)’), ‘|’, ‘</U><U></U></root>’ AS XML) AS xml_
FROM @sql_xml.nodes(‘/root/U’) f(x)
WHERE f.x.value(‘.’, ‘VARCHAR(MAX)’) <> »
)T
OUTER APPLY T.xml_.nodes(‘root’) as X(Y)
|
Este ejemplo es similar al anterior pero hemos utilizado la tubería «|» como delimitador con un segundo delimitador, el dólar «$». Aquí, el parámetro de entrada es la combinación de dos columnas, role_id y user_id. Como vemos a continuación, user_id y role_id están en una columna separada en el conjunto de resultados de la tabla:

Podemos utilizar cualquier carácter en la función anterior, como una sola cadena separada por caracteres o una combinación de cadenas separadas por caracteres. Un desarrollador debe simplemente reemplazar el carácter en las sentencias T-SQL anteriores. Siga los pasos descritos aquí para convertir cualquier cadena delimitada en una lista. Simplemente recuerde que la función XML de SQL Server acepta una entrada de cadena y la cadena de entrada se delimitará con el separador especificado utilizando la función tabular.

Ver todas las entradas de Jignesh Raiyani
This example is similar to the above example but we have utilized pipe «|” as a delimiter with a second delimiter, dollar «$”. Here, the input parameter is the combination of two-columns, role_id, and user_id. As we see below, user_id and role_id are in a separate column in the table result set:
We can use any character in the above function, such as a single character-separated string or combination of character-separated strings. A developer must simply replace the character in the T-SQL statements above. Follow the steps described here to convert any delimited string to a list. Simply remember that the XML function of SQL Server accepts a string input and the input string will be delimited with the specified separator using the tabular function.
View all posts by Jignesh Raiyani
, ‘</U><U></U></root>’ AS XML)
This example is similar to the above example but we have utilized pipe «|” as a delimiter with a second delimiter, dollar «$”. Here, the input parameter is the combination of two-columns, role_id, and user_id. As we see below, user_id and role_id are in a separate column in the table result set:
We can use any character in the above function, such as a single character-separated string or combination of character-separated strings. A developer must simply replace the character in the T-SQL statements above. Follow the steps described here to convert any delimited string to a list. Simply remember that the XML function of SQL Server accepts a string input and the input string will be delimited with the specified separator using the tabular function.
View all posts by Jignesh Raiyani
This example is similar to the above example but we have utilized pipe «|” as a delimiter with a second delimiter, dollar «$”. Here, the input parameter is the combination of two-columns, role_id, and user_id. As we see below, user_id and role_id are in a separate column in the table result set:
We can use any character in the above function, such as a single character-separated string or combination of character-separated strings. A developer must simply replace the character in the T-SQL statements above. Follow the steps described here to convert any delimited string to a list. Simply remember that the XML function of SQL Server accepts a string input and the input string will be delimited with the specified separator using the tabular function.
View all posts by Jignesh Raiyani