Biologie I

Figure 1. Un nucléotide est constitué de trois composants : une base azotée, un sucre pentose et un ou plusieurs groupes phosphates. Les résidus carbonés du pentose sont numérotés de 1′ à 5′ (le nombre premier distingue ces résidus de ceux de la base, qui sont numérotés sans utiliser de notation première). La base est attachée à la position 1′ du ribose, et le phosphate est attaché à la position 5′. Lorsqu’un polynucléotide est formé, le phosphate 5′ du nucléotide entrant se fixe au groupe hydroxyle 3′ à l’extrémité de la chaîne en croissance. Deux types de pentose sont présents dans les nucléotides, le désoxyribose (présent dans l’ADN) et le ribose (présent dans l’ARN). Le désoxyribose a une structure similaire à celle du ribose, mais il possède un H au lieu d’un OH en position 2′. Les bases peuvent être divisées en deux catégories : les purines et les pyrimidines. Les purines ont une structure à double cycle, et les pyrimidines ont un seul cycle.
Les bases azotées, composants importants des nucléotides, sont des molécules organiques et sont ainsi nommées car elles contiennent du carbone et de l’azote. Elles sont des bases parce qu’elles contiennent un groupe amino qui a le potentiel de se lier à un hydrogène supplémentaire, et ainsi, diminue la concentration d’ions hydrogène dans son environnement, le rendant plus basique. Chaque nucléotide de l’ADN contient l’une des quatre bases azotées possibles : adénine (A), guanine (G), cytosine (C) et thymine (T). Les nucléotides de l’ARN contiennent également l’une des quatre bases possibles : adénine, guanine, cytosine et uracile (U) plutôt que thymine.
L’adénine et la guanine sont classées parmi les purines. La structure primaire d’une purine est constituée de deux cycles carbone-azote. La cytosine, la thymine et l’uracile sont classées comme des pyrimidines qui ont un seul cycle carbone-azote comme structure primaire (figure 1). Différents groupes fonctionnels sont attachés à chacun de ces cycles carbone-azote de base. En abrégé de biologie moléculaire, les bases azotées sont simplement connues par leurs symboles A, T, G, C et U. L’ADN contient A, T, G et C tandis que l’ARN contient A, U, G et C.
Le sucre pentose de l’ADN est le désoxyribose, et dans l’ARN, le sucre est le ribose (figure 1). La différence entre ces sucres est la présence du groupe hydroxyle sur le deuxième carbone du ribose et de l’hydrogène sur le deuxième carbone du désoxyribose. Les atomes de carbone de la molécule de sucre sont numérotés 1′, 2′, 3′, 4′ et 5′ (1′ se lit comme » un premier « ). Le résidu phosphate est attaché au groupe hydroxyle du carbone 5′ d’un sucre et au groupe hydroxyle du carbone 3′ du sucre du nucléotide suivant, ce qui forme une liaison phosphodiester 5′-3′. La liaison phosphodiester n’est pas formée par simple réaction de déshydratation comme les autres liaisons reliant les monomères des macromolécules : sa formation implique l’élimination de deux groupes phosphates. Un polynucléotide peut comporter des milliers de ces liaisons phosphodiester.
Structure à double hélice de l’ADN
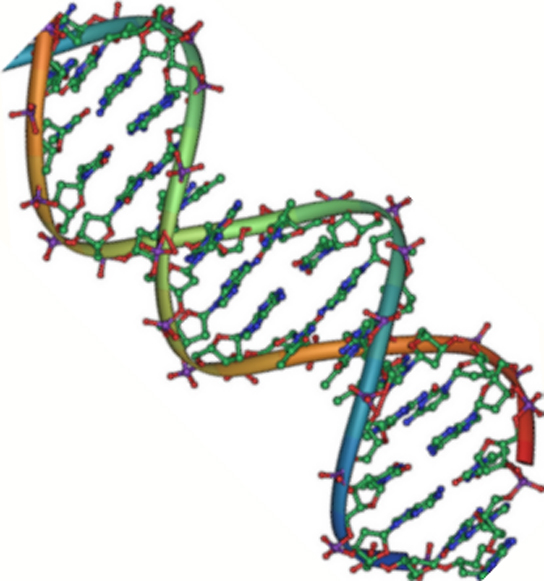
Figure 2. L’ADN est une double hélice antiparallèle. Le squelette phosphate (les lignes courbes) est à l’extérieur, et les bases sont à l’intérieur. Chaque base interagit avec une base du brin opposé. (crédit : Jerome Walker/Dennis Myts)
L’ADN a une structure en double hélice (figure 2). Le sucre et le phosphate se trouvent à l’extérieur de l’hélice, formant le squelette de l’ADN. Les bases azotées sont empilées à l’intérieur, comme les marches d’un escalier, par paires ; les paires sont liées les unes aux autres par des liaisons hydrogène. Chaque paire de bases dans la double hélice est séparée de la paire de bases suivante par 0,34 nm.
Les deux brins de l’hélice sont dirigés dans des directions opposées, ce qui signifie que l’extrémité carbonée 5′ d’un brin fera face à l’extrémité carbonée 3′ de son brin correspondant. (On parle d’orientation antiparallèle et ce phénomène est important pour la réplication de l’ADN et dans de nombreuses interactions entre acides nucléiques.)
Seuls certains types d’appariement de bases sont autorisés. Par exemple, une certaine purine ne peut s’apparier qu’avec une certaine pyrimidine. Cela signifie que A peut s’apparier avec T, et que G peut s’apparier avec C, comme le montre la figure 3. C’est ce qu’on appelle la règle de la complémentarité des bases. En d’autres termes, les brins d’ADN sont complémentaires les uns des autres. Si la séquence d’un brin est AATTGGCC, le brin complémentaire aura la séquence TTAACCGG. Lors de la réplication de l’ADN, chaque brin est copié, ce qui donne une double hélice d’ADN fille contenant un brin d’ADN parental et un brin nouvellement synthétisé.
Pratique
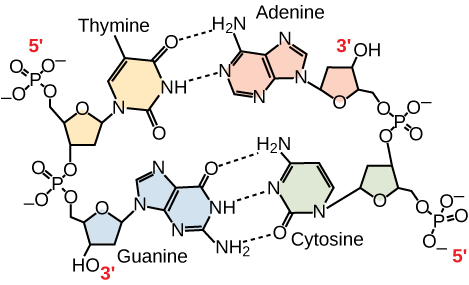
Figure 3. Dans une molécule d’ADN double brin, les deux brins sont antiparallèles l’un à l’autre, de sorte qu’un brin va de 5′ en 3′ et l’autre de 3′ en 5′. Le squelette phosphate est situé à l’extérieur, et les bases sont au milieu. L’adénine forme des liaisons hydrogène (ou paires de bases) avec la thymine, et la guanine forme des paires de bases avec la cytosine.
Une mutation se produit, et la cytosine est remplacée par l’adénine. Quel impact pensez-vous que cela aura sur la structure de l’ADN ?
ARN
L’acide ribonucléique, ou ARN, est principalement impliqué dans le processus de synthèse des protéines sous la direction de l’ADN. L’ARN est généralement monocaténaire et est constitué de ribonucléotides qui sont liés par des liaisons phosphodiesters. Un ribonucléotide de la chaîne de l’ARN contient du ribose (le sucre pentose), l’une des quatre bases azotées (A, U, G et C) et le groupe phosphate.
Il existe quatre grands types d’ARN : l’ARN messager (ARNm), l’ARN ribosomal (ARNr), l’ARN de transfert (ARNt) et le microARN (miARN). Le premier, l’ARNm, transmet le message de l’ADN, qui contrôle toutes les activités cellulaires d’une cellule. Si une cellule a besoin de synthétiser une certaine protéine, le gène de ce produit est activé et l’ARN messager est synthétisé dans le noyau. La séquence de base de l’ARN est complémentaire de la séquence codante de l’ADN à partir duquel elle a été copiée. Toutefois, dans l’ARN, la base T est absente et remplacée par U. Si le brin d’ADN a une séquence AATTGCGC, la séquence de l’ARN complémentaire est UUAACGCG. Dans le cytoplasme, l’ARNm interagit avec les ribosomes et d’autres machineries cellulaires (figure 4).
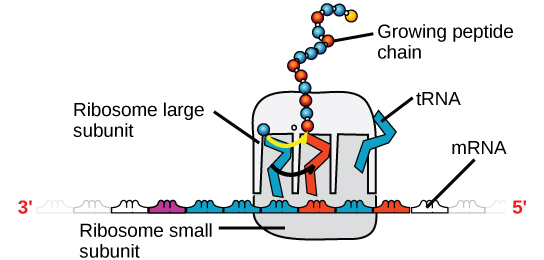
Figure 4. Un ribosome est composé de deux parties : une grande sous-unité et une petite sous-unité. L’ARNm se trouve entre les deux sous-unités. Une molécule d’ARNt reconnaît un codon sur l’ARNm, s’y lie par appariement de bases complémentaires et ajoute le bon acide aminé à la chaîne peptidique en croissance.
L’ARNm est lu par ensembles de trois bases appelés codons. Chaque codon code pour un seul acide aminé. De cette façon, l’ARNm est lu et le produit protéique est fabriqué. L’ARN ribosomal (ARNr) est un constituant majeur des ribosomes sur lesquels se fixe l’ARNm. L’ARNr assure le bon alignement de l’ARNm et des ribosomes ; l’ARNr du ribosome a également une activité enzymatique (peptidyl transférase) et catalyse la formation des liaisons peptidiques entre deux acides aminés alignés. L’ARN de transfert (ARNt) est l’un des plus petits des quatre types d’ARN, généralement long de 70 à 90 nucléotides. Il transporte le bon acide aminé jusqu’au site de synthèse de la protéine. C’est l’appariement des bases entre l’ARNt et l’ARNm qui permet d’insérer l’acide aminé correct dans la chaîne polypeptidique. Les micro-ARN sont les plus petites molécules d’ARN et leur rôle implique la régulation de l’expression des gènes en interférant avec l’expression de certains messages ARNm.