Création d’histogrammes à l’aide de R
Lorsque vous explorez un ensemble de données, vous voudrez souvent avoir une compréhension rapide de la distribution de certaines variables numériques au sein de celui-ci. Une façon courante de visualiser la distribution d’une seule variable numérique est d’utiliser un histogramme. Un histogramme divise les valeurs d’une variable numérique en « cases » et compte le nombre d’observations qui se trouvent dans chaque case. En visualisant ces comptages binnés de manière colonnaire, nous pouvons obtenir un sens très immédiat et intuitif de la distribution des valeurs au sein d’une variable.
Cette recette vous montrera comment procéder pour créer un histogramme à l’aide de R. Plus précisément, vous utiliserez la fonction hist() de R et ggplot2.
Dans notre exemple, vous allez visualiser la distribution de la durée des sessions pour un site Web. Les étapes de cette recette sont divisées en plusieurs sections :
- Traitement des données
- Exploration des données & Préparation
- Visualisation des données
Vous pouvez trouver des implémentations de toutes les étapes décrites ci-dessous dans cet exemple de rapport Mode. Commençons.
Mélange de données
Vous utiliserez SQL pour mélanger les données dont vous aurez besoin pour notre analyse. Pour cet exemple, vous utiliserez le jeu de données sessions disponible dans l’entrepôt de données publiques de Mode. À l’aide du navigateur de schémas de l’éditeur, assurez-vous que votre source de données est définie sur la source de données de l’entrepôt public de Mode et exécutez la requête suivante pour arracher vos données :
`select *from modeanalytics.sessions`Une fois l’exécution de la requête SQL terminée, renommez votre requête SQL en Sessions afin de pouvoir l’identifier facilement dans le carnet R.
Exploration des données & Préparation
Maintenant que vous avez brassé vos données, vous êtes prêt à passer dans le notebook R pour préparer vos données à la visualisation. Mode pipe automatiquement les résultats de vos requêtes SQL dans un dataframe R attribué à la variable datasets. Vous pouvez utiliser la ligne de R suivante pour accéder aux résultats de votre requête SQL sous forme de dataframe et les affecter à une nouvelle variable:
`sessions <- datasets]`Visualisation des données
Pour créer un histogramme, nous utiliserons la fonction hist() de R. Puisque vous êtes seulement intéressé à visualiser la distribution de la variable session_duration_seconds, vous passerez le nom de la colonne à la fonction hist() pour limiter la sortie de visualisation à la variable d’intérêt :
`# Using hist() function in base graphics to make a histogramhistinfo=hist(sessions$session_duration_seconds, main="Histogram with Default Parameters")`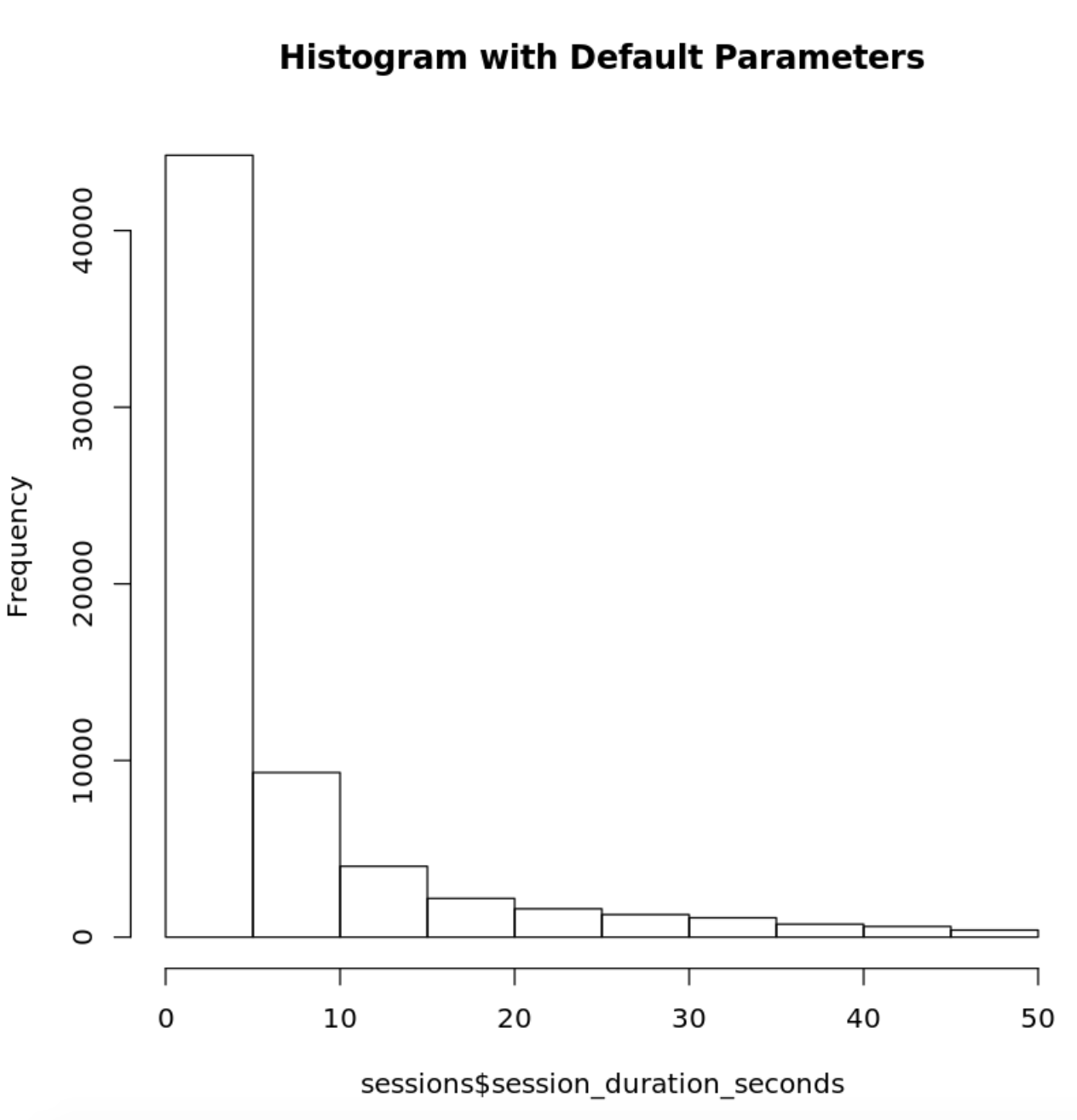
Vous pouvez personnaliser davantage l’apparence de votre histogramme en fournissant à la fonction hist() des paramètres supplémentaires :
`hist(sessions$session_duration_seconds, main="Adding grid lines and ticks", xlab="Session Duration (in seconds)", ylab= "Count", xlim=c(0,55), ylim=c(0, 49000), col="lightgrey")axis(4, labels=FALSE, col = "lightgrey", lty=2, tck=1)`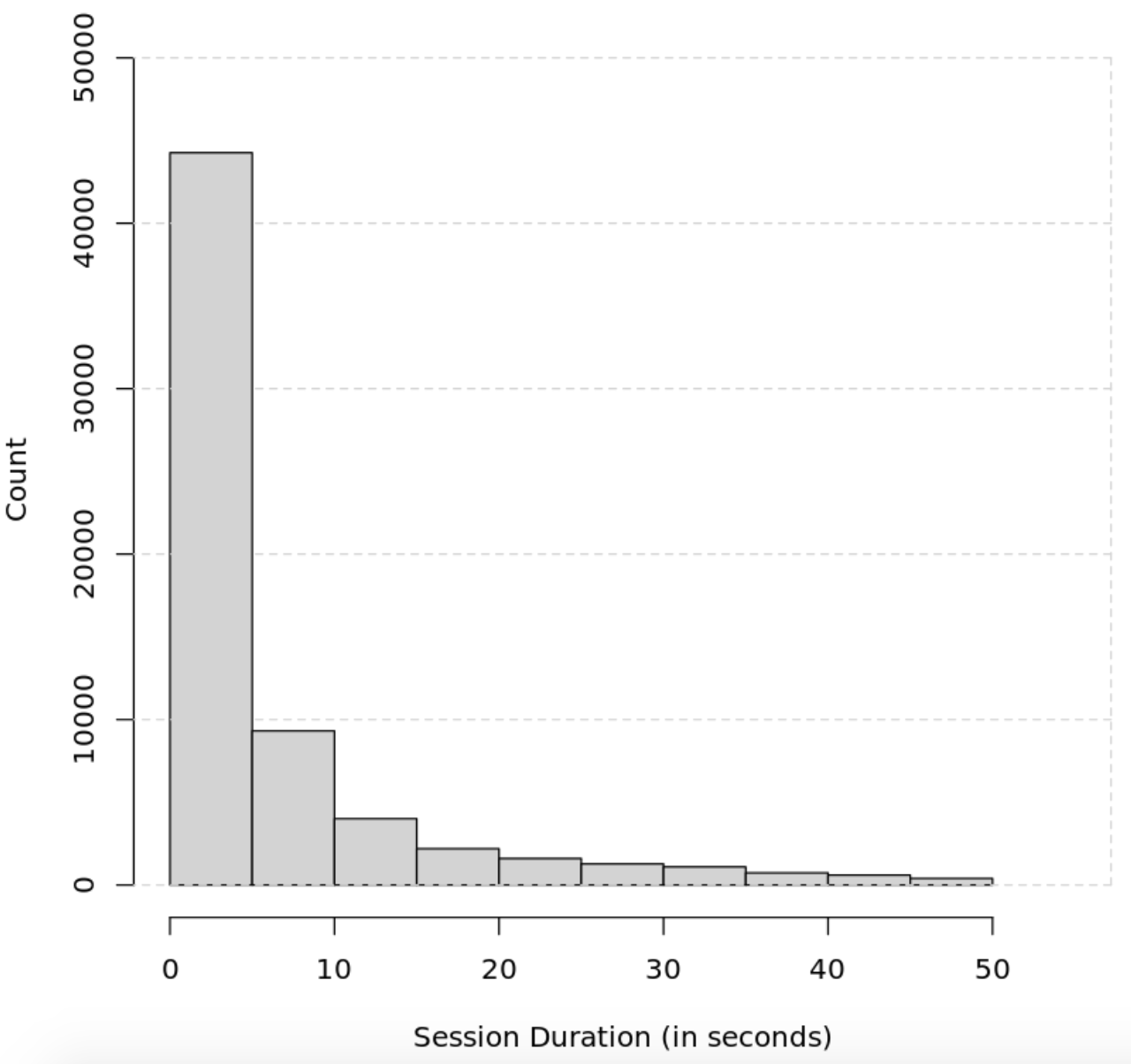
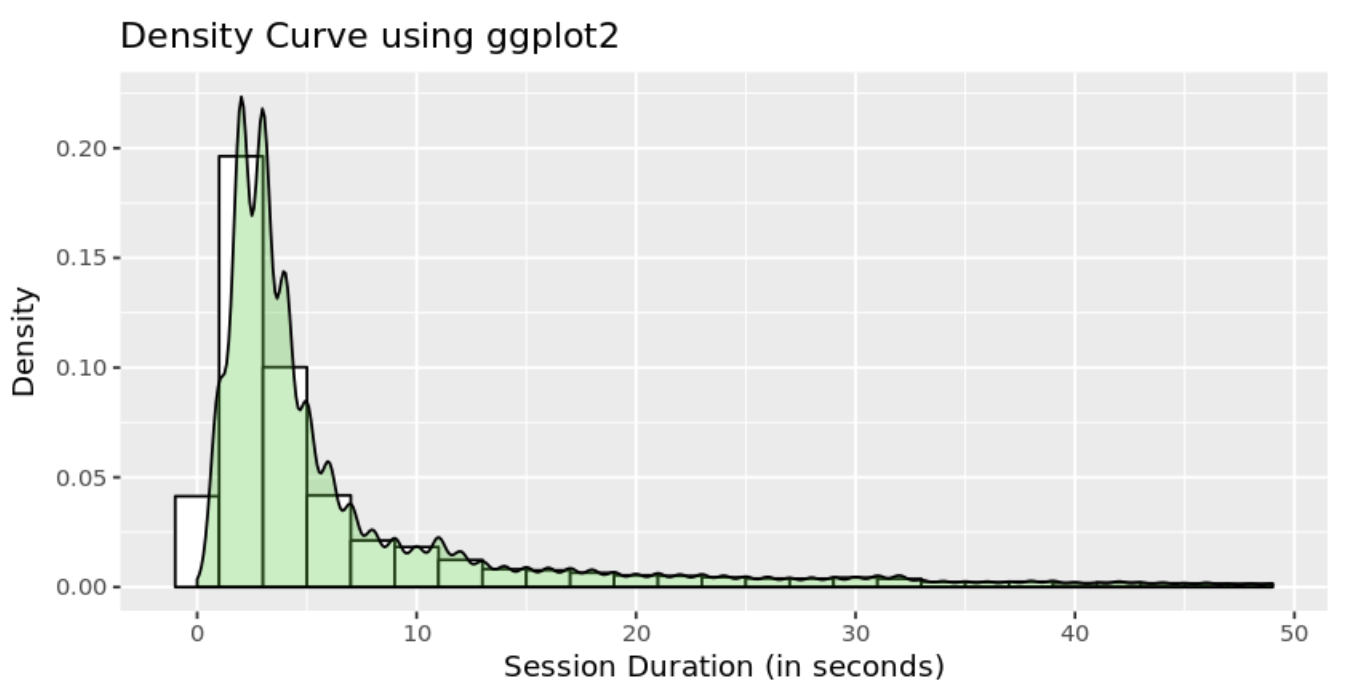
Vous pouvez également utiliser la fonctionnalité native de création d’histogrammes de ggplot2 pour créer et styliser des histogrammes en R avec des fonctionnalités supplémentaires comme les estimations de densité de noyau :
`p <- ggplot(sessions, aes(x=session_duration_seconds)) + geom_histogram(aes(y=..density..), # Histogram with density instead of count on y-axis binwidth=2, colour="black", fill="white") + geom_density(alpha=.3, fill="#32CD32")p + labs(x = "Session Duration (in seconds)", y = "Density", title = "Density Curve using ggplot2") + coord_fixed(ratio = 100)ggsave("ggtest.png", p, width = 5, height = 8, dpi = 1200)`