Déclaration de mise à jour SQL avec jointure dans SQL Server vs Oracle vs PostgreSQL
Par : Andrea Gnemmi | Mis à jour : 2021-01-04 | Commentaires | Connexe : Plus > Autres plateformes de base de données
Problème
Comme la plupart des DBA et des développeurs qui travaillent à la fois avec SQL Server et Oraclele savent déjà, il existe quelques différences dans la façon dont vous mettez à jour les lignes en utilisant une jointureentre SQL Server et Oracle. Notamment, cela n’est pas possible avec Oracle sans une certaine finesse. PostgreSQL a une approche ANSI SQL similaire à celle de SQL Server. Dans cet article, nous comparons la façon d’exécuter les mises à jour lors de l’utilisation d’une jointure entre SQL Server, Oracle etPostgreSQL.
Solution
Vous trouverez ci-dessous une comparaison des différentes syntaxes utilisées pour mettre à jour les données lors de l’utilisation d’une jointure.
Une remarque concernant la terminologie : dans Oracle, nous n’aurons pas une base de données nommée Chinook,mais un schéma ou plus correctement un Utilisateur. Dans Oracle, à moins d’utiliser des bases de données enfichables, vous ne pouvez avoir qu’une seule base de données par instance.
A des fins de test, j’utiliserai l’exemple de base de données téléchargeable gratuitement Chinook, car il est disponible dans plusieurs formats de SGBDR. Il s’agit d’une simulation d’un magasin de médias numériques avec quelques échantillons de données. Tout ce que vous avez à faire est de télécharger la version dont vous avez besoin et d’exécuter les scripts pour la structure de données ainsi que l’insertion des données.
SQL Server Update Statement with Join
Nous allons commencer par un rappel rapide du fonctionnement d’une instruction SQL UPDATE avec un JOIN dans SQL Server.
Normalement, nous mettons à jour une ligne ou plusieurs lignes dans une table avec un filtre basé sur une clauseWHERE. Nous vérifions qu’il n’y a pas d’erreur et nous constatons que la ville de Vienne n’existe pas. Mais plutôt Wien en allemand ou Vienna en anglais :
select customerid, FirstName,LastName, Address, city,countryfrom dbo.Customerwhere city='Vienne'

Nous pouvons corriger cela avec une instruction UPDATE normale telle que :
update dbo.Customerset city='Wien'where city='Vienne'

Nous pouvons également mettre à jour la table des factures en fonction d’un client. Tout d’abord, schématisons les données avec une simple requête SELECT:
select invoice.BillingCityfrom invoiceinner join customer on invoice.CustomerId=customer.CustomerIdwhere customer.City='Vienne'
Nous avons ce résultat :
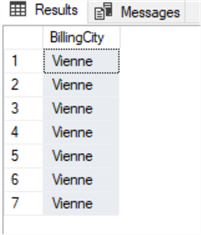
À ce stade, nous pouvons effectuer une MISE À JOUR en utilisant la même clause JOIN que la requête SELECT que nous venons de faire. Je sais que nous aurions pu utiliser un simple UPDATE sur la seule table, mais cet exemple montre simplement comment cela peut être fait en faisant un JOIN :
update invoiceset invoice.BillingCity='Wien'from invoiceinner join customeron invoice.CustomerId=customer.CustomerIdwhere customer.City='Vienne'

Nous pouvons même utiliser une CTE (Common Table Expression) dans la clause JOIN afin d’avoir un filtre particulier.
Par exemple, supposons que nous devions accorder une remise spéciale sur la facture totale pour les clients autrichiens qui ont dépensé plus de 20 dollars en Rock et Metal(genre 1 et 3). Le sous-ensemble est facilement extrait avec la requête suivante:
select Invoice.CustomerId,sum(invoiceline.UnitPrice*Quantity) as genretotalfrom invoiceinner join InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceIdinner join Track on Track.TrackId=InvoiceLine.TrackIdinner join customer on customer.CustomerId=Invoice.CustomerIdwhere country='Austria' and GenreId in (1,3)group by Invoice.CustomerIdhaving sum(invoiceline.UnitPrice*Quantity)>20
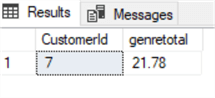
Supposons que nous voulions appliquer une remise de 20%. Nous pouvons l’appliquer en mettant à jour le tableau des factures totales sur la base de la requête ci-dessus à l’aide du CTE ci-dessous:
; with discount as( select Invoice.CustomerId, sum(invoiceline.UnitPrice*Quantity) as genretotal from invoice inner join InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceId inner join Track on Track.TrackId=InvoiceLine.TrackId inner join customer on customer.CustomerId=Invoice.CustomerId where country='Austria' and GenreId in (1,3) group by Invoice.CustomerId having sum(invoiceline.UnitPrice*Quantity)>20)update Invoiceset total=total*0.8from Invoiceinner join discount on Invoice.CustomerId=discount.CustomerId
Oracle Update Statement with Join
Comment cela fonctionne-t-il dans Oracle ? La réponse est assez simple : dans Oracle, cette syntaxe deUPDATE statementwith a JOIN n’est pas prise en charge.
Nous devons faire quelques raccourcis afin de faire quelque chose de similaire. Nous pouvons faire usage d’une sous-requête et d’un filtre IN. Par exemple, nous pouvons transformer le premier UPDATE avec le JOIN que nous avons utilisé dans SQL Server.
D’abord, vérifions avec la même requête SELECT les données de la table Invoice dans Oracle :
select invoice.BillingCityfrom chinook.invoiceinner join chinook.customer on invoice.CustomerId=customer.CustomerIdwhere customer.City='Vienne';
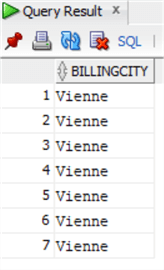
Nous allons transformer l’instruction UPDATE en utilisant la requête ci-dessus comme sous-requête, mais nous allons extraire la clé primaire Invoiceid afin d’effectuer la mise à jour :
update chinook.invoiceset invoice.BillingCity='Wien'where invoiceid in ( select invoiceid from chinook.invoice inner join chinook.customer on invoice.CustomerId=customer.CustomerId where customer.City='Vienne' );
N’oubliez pas de commiter. Comme nous sommes sous Oracle, il n’y a pas d’auto commit par défaut :
commit;
C’était assez facile, mais supposons que nous ayons besoin d’un UPDATE basé sur une autre grande table et d’utiliser la valeur de l’autre table.
Supposons que nous voulions faire le même UPDATEcomme nous l’avons fait avec le CTE sur SQL Server, nous pouvons surmonter le problème du JOINavec ce code :
update ( select invoice.customerid,total from chinook.Invoice inner join ( select Invoice.Cust merId as customerid_sub, sum(invoiceline.UnitPrice*Quantity) as genretotal from chinook.invoice inner join chinook.InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceId inner join chinook.Track on Track.TrackId=InvoiceLine.TrackId inner join chinook.customer on customer.CustomerId=Invoice.CustomerId where country='Austria' and GenreId in (1,3) group by Invoice.CustomerId having sum(invoiceline.UnitPrice*Quantity)>20 ) on Invoice.CustomerId=Customerid_sub )set total=total*0.8;
commit;
Comme vous avez pu le remarquer, j’ai transformé le CTE en une sous-requête et je l’ai joint à la table Invoice de manière similaire à la mise à jour effectuée avec SQL Server. Mais cette fois-ci, c’est une instruction select avec la clé primaire et le total que nous souhaitons mettre à jour. J’ai entré ce résultat comme table à mettre à jour. C’est une solution de contournement, mais ça marche ! La seule chose à laquelle vous devez faire attention est de vous assurer que les résultats sont uniques et que vous n’essayez pas de mettre à jour plus de lignes que celles dont vous avez besoin. C’est pourquoi je fais toujours unselect avant de vérifier combien de lignes doivent être mises à jour.
Il existe une solution plus élégante, faisant appel à l’instruction MERGE. La syntaxeest similaire à celle de MERGE dans SQL Server, nous utiliserons donc le même UPDATE que dans le dernier exemple.Cela devrait être écrit comme ceci:
MERGE INTO chinook.InvoiceUSING ( select Invoice.CustomerId as customerid_sub, sum(invoiceline.UnitPrice*Quantity) as genretotal from chinook.invoice inner join chinook.InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceId inner join chinook.Track on Track.TrackId=InvoiceLine.TrackId inner join chinook.customer on customer.CustomerId=Invoice.CustomerId where country='Austria' and GenreId in (1,3) group by Invoice.CustomerId having sum(invoiceline.UnitPrice*Quantity)>20 ) ON (Invoice.CustomerId=Customerid_sub)WHEN MATCHED THENUPDATE set total=total*0.8;
Comme vous pouvez le voir, c’est plus lisible que la solution précédente. Dans SQL Server, les performances des instructions MERGE ne sont pas toujours les meilleures. Gardez cela à l’esprit lorsque vous l’utilisez et testez-la avant de l’utiliser dans un environnement de production.
PostgreSQL Update Statement with Join
Qu’en est-il de PostgreSQL ? Dans ce cas, les mêmes concepts qui fonctionnent dans SQL Serverfont le travail également sur PostgreSQL. Nous avons juste quelques différences avec la syntaxe car nous ne spécifions pas la jointure. Mais nous utilisons l’ancienne syntaxe de jointure avec la clause WHERE.
Adaptons le même code SQL que nous avons utilisé sur SQL Server et testons-le sur la base de données Chinook sur PostgreSQL :
update "Invoice"set "BillingCity"='Wien'from "Customer"where "Invoice"."CustomerId"="Customer"."CustomerId"and "Customer"."City"='Vienne'
Dans ce cas, nous n’avons pas besoin de spécifier la première table sur laquelle nous ferons la mise à jour. Le reste est exactement le même que dans SQL Server.
Testons le code avec le CTE (veuillez noter que dans PostgreSQL nous devons mettre entre guillemets tous les noms de colonnes qui ont été créés avec une majuscule sinon il ne les reconnaîtra pas !):
; with discount as( select "Invoice"."CustomerId", sum("InvoiceLine"."UnitPrice"*"Quantity") as genretotal from "Invoice" inner join "InvoiceLine" on "Invoice"."InvoiceId"="InvoiceLine"."InvoiceId" inner join "Track" on "Track"."TrackId"="InvoiceLine"."TrackId" inner join "Customer" on "Customer"."CustomerId"="Invoice"."CustomerId" where "Country"='Austria' and "GenreId" in (1,3) group by "Invoice"."CustomerId" having sum("InvoiceLine"."UnitPrice"*"Quantity")>20 )update "Invoice"set "Total"="Total"*0.8from discountwhere "Invoice"."CustomerId"=discount."CustomerId"

Résumé
Dans cette astuce, nous avons vu les différences de syntaxe pour les instructions UPDATE lors de l’utilisation d’un JOIN dans SQL Server, Oracle et PostgreSQL.
Prochaines étapes
- Il existe d’autres façons de mettre à jour avec des jointures dans Oracle, notamment en utilisant la clauseWHERE EXISTS avec des sous-requêtes. Mais c’est similaire à ce qui a été réalisé en utilisant la syntaxe que j’ai employée dans mon exemple de code.
- Veuillez noter que j’ai utilisé SSMS pour SQL Server, SQL Developer pour Oracleet PGAdmin pour PostgreSQL. Tous sont disponibles gratuitement en téléchargement.
Dernière mise à jour : 2021-01-04


A propos de l’ auteur
 Andrea Gnemmi est un professionnel des bases de données et des entrepôts de données avec près de 20 ans d’expérience, ayant débuté sa carrière dans l’administration de bases de données avec SQL Server 2000.
Andrea Gnemmi est un professionnel des bases de données et des entrepôts de données avec près de 20 ans d’expérience, ayant débuté sa carrière dans l’administration de bases de données avec SQL Server 2000.Voir tous mes conseils
- Plus de conseils DBA SQL Server…
.