Dichiarazione di aggiornamento SQL con join in SQL Server vs Oracle vs PostgreSQL
Da: Andrea Gnemmi | Aggiornato: 2021-01-04 | Commenti | Correlati: Altro > Altre piattaforme di database
Problema
Come la maggior parte dei DBA e degli sviluppatori che lavorano sia con SQL Server che con Oracle già sanno, ci sono alcune differenze nel modo di aggiornare le righe usando un join tra SQL Server e Oracle. In particolare, questo non è possibile con Oracle senza qualche finezza. PostgreSQL ha un approccio ANSI SQL simile a quello di SQL Server. In questo articolo confrontiamo come eseguire gli aggiornamenti quando si usa un join tra SQL Server, Oracle e PostgreSQL.
Soluzione
Di seguito faremo un confronto delle diverse sintassi usate per aggiornare i dati quando si usa un join.
Una nota sulla terminologia: in Oracle non avremo un database chiamato Chinook, ma uno schema o più propriamente un Utente. In Oracle, a meno che non si usino i Pluggable Databases, si può avere un solo database per istanza.
Per scopi di test userò il campione di database scaricabile gratuitamente Chinook, poiché è disponibile in diversi formati RDBMS. È una simulazione di un negozio di media digitali con alcuni dati di esempio. Tutto quello che dovete fare è scaricare la versione di cui avete bisogno ed eseguire gli script per la struttura dei dati e l’inserimento dei dati.
SQL Server Update Statement with Join
Iniziamo con un veloce promemoria di come funziona un SQL UPDATE statement con una JOIN in SQL Server.
Normalmente aggiorniamo una riga o più righe in una tabella con un filtro basato su una clausolaWHERE. Controlliamo un errore e scopriamo che non esiste una città come Vienne. Ma piuttosto, Wien in tedesco o Vienna in inglese:
select customerid, FirstName,LastName, Address, city,countryfrom dbo.Customerwhere city='Vienne'

Possiamo correggere questo con una normale istruzione UPDATE come:
update dbo.Customerset city='Wien'where city='Vienne'

Possiamo anche aggiornare la tabella delle fatture in base a un cliente. Per prima cosa, cerchiamo i dati con una semplice query SELECT:
select invoice.BillingCityfrom invoiceinner join customer on invoice.CustomerId=customer.CustomerIdwhere customer.City='Vienne'
Abbiamo questo risultato:
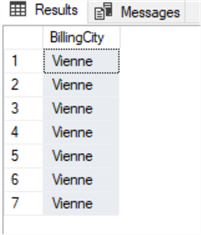
A questo punto possiamo fare un UPDATE usando la stessa clausola JOIN della query SELECT che abbiamo appena fatto. So che avremmo potuto usare un semplice UPDATE su una tabella, ma questo esempio mostra solo come può essere fatto quando si fa una JOIN:
update invoiceset invoice.BillingCity='Wien'from invoiceinner join customeron invoice.CustomerId=customer.CustomerIdwhere customer.City='Vienne'

Possiamo anche usare una CTE (Common Table Expression) nella clausola JOIN per avere qualche filtro particolare.
Per esempio, supponiamo di dover fare uno sconto speciale sul totale della fattura per i clienti austriaci che hanno speso più di 20 dollari in Rock and Metal (genere 1 e 3). Il sottoinsieme si estrae facilmente con la seguente query:
select Invoice.CustomerId,sum(invoiceline.UnitPrice*Quantity) as genretotalfrom invoiceinner join InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceIdinner join Track on Track.TrackId=InvoiceLine.TrackIdinner join customer on customer.CustomerId=Invoice.CustomerIdwhere country='Austria' and GenreId in (1,3)group by Invoice.CustomerIdhaving sum(invoiceline.UnitPrice*Quantity)>20
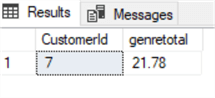
Supponiamo di voler applicare uno sconto del 20%. Possiamo applicarlo aggiornando il totale della tabella delle fatture in base alla query di cui sopra utilizzando il seguente CTE:
; with discount as( select Invoice.CustomerId, sum(invoiceline.UnitPrice*Quantity) as genretotal from invoice inner join InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceId inner join Track on Track.TrackId=InvoiceLine.TrackId inner join customer on customer.CustomerId=Invoice.CustomerId where country='Austria' and GenreId in (1,3) group by Invoice.CustomerId having sum(invoiceline.UnitPrice*Quantity)>20)update Invoiceset total=total*0.8from Invoiceinner join discount on Invoice.CustomerId=discount.CustomerId
Oracle Update Statement with Join
Come funziona in Oracle? La risposta è abbastanza semplice: in Oracle questa sintassi diUPDATE statementwith a JOIN non è supportata.
Dobbiamo fare alcune scorciatoie per fare qualcosa di simile. Possiamo fare uso di una sottoquery e di un filtro IN. Per esempio, possiamo trasformare il primo UPDATE con la JOIN che abbiamo usato in SQL Server.
Prima, controlliamo con la stessa query SELECT i dati della tabella Invoice in Oracle:
select invoice.BillingCityfrom chinook.invoiceinner join chinook.customer on invoice.CustomerId=customer.CustomerIdwhere customer.City='Vienne';
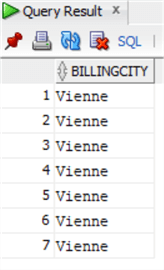
Trasformeremo l’istruzione UPDATE usando la query precedente come sottoquery, ma estrarremo la chiave primaria Invoiceid per fare l’aggiornamento:
update chinook.invoiceset invoice.BillingCity='Wien'where invoiceid in ( select invoiceid from chinook.invoice inner join chinook.customer on invoice.CustomerId=customer.CustomerId where customer.City='Vienne' );
Non dimenticare di fare il commit. Dato che siamo in Oracle, non c’è un commit automatico per default:
commit;
Questo è stato abbastanza facile, ma supponiamo di aver bisogno di un UPDATE basato su un’altra grande tabella e di usare il valore nell’altra tabella.
Supponiamo di voler fare lo stesso UPDATE come abbiamo fatto con il CTE su SQL Server, possiamo superare il problema JOIN con questo codice:
update ( select invoice.customerid,total from chinook.Invoice inner join ( select Invoice.Cust merId as customerid_sub, sum(invoiceline.UnitPrice*Quantity) as genretotal from chinook.invoice inner join chinook.InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceId inner join chinook.Track on Track.TrackId=InvoiceLine.TrackId inner join chinook.customer on customer.CustomerId=Invoice.CustomerId where country='Austria' and GenreId in (1,3) group by Invoice.CustomerId having sum(invoiceline.UnitPrice*Quantity)>20 ) on Invoice.CustomerId=Customerid_sub )set total=total*0.8;
commit;
Come avrete notato, ho trasformato la CTE in una subquery e l’ho unita alla tabella Invoice come l’aggiornamento fatto con SQL Server. Ma questa volta si tratta di un’istruzione select con la chiave primaria e il totale che vogliamo aggiornare. Ho messo questo risultato come tabella da aggiornare. È un workaround, ma funziona! L’unica cosa a cui dovete fare attenzione è assicurarvi che i risultati siano unici e che non stiate cercando di aggiornare più righe di quelle che vi servono. Questo è il motivo per cui faccio sempre un aselect prima di controllare quante righe devono essere aggiornate.
C’è una soluzione più elegante, facendo uso dell’istruzione MERGE. La sintassi è simile a quella di MERGE in SQL Server, quindi useremo lo stesso UPDATE dell’ultimo esempio, che dovrebbe essere scritto così:
MERGE INTO chinook.InvoiceUSING ( select Invoice.CustomerId as customerid_sub, sum(invoiceline.UnitPrice*Quantity) as genretotal from chinook.invoice inner join chinook.InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceId inner join chinook.Track on Track.TrackId=InvoiceLine.TrackId inner join chinook.customer on customer.CustomerId=Invoice.CustomerId where country='Austria' and GenreId in (1,3) group by Invoice.CustomerId having sum(invoiceline.UnitPrice*Quantity)>20 ) ON (Invoice.CustomerId=Customerid_sub)WHEN MATCHED THENUPDATE set total=total*0.8;
Come potete vedere, è più leggibile della soluzione precedente. In SQL Server, le prestazioni delle istruzioni MERGE non sono sempre le migliori. Tenetelo a mente quando lo usate e testatelo prima di usarlo in un ambiente di produzione.
PostgreSQL Update Statement with Join
Che dire di PostgreSQL? In questo caso, gli stessi concetti che funzionano in SQL Server funzionano anche su PostgreSQL. Abbiamo solo qualche differenza con la sintassi, dato che non specifichiamo il join. Ma usiamo la vecchia sintassi di unione con la clausola WHERE.
Adattiamo lo stesso codice SQL che abbiamo usato su SQL Server e testiamolo sul database Chinook su PostgreSQL:
update "Invoice"set "BillingCity"='Wien'from "Customer"where "Invoice"."CustomerId"="Customer"."CustomerId"and "Customer"."City"='Vienne'
In questo caso non abbiamo bisogno di specificare la prima tabella su cui faremo l’aggiornamento. Il resto è esattamente lo stesso che in SQL Server.
Testiamo il codice con la CTE (si noti che in PostgreSQL dobbiamo mettere tra virgolette tutti i nomi di colonna che sono stati creati con una lettera maiuscola, altrimenti non li riconoscerà!):
; with discount as( select "Invoice"."CustomerId", sum("InvoiceLine"."UnitPrice"*"Quantity") as genretotal from "Invoice" inner join "InvoiceLine" on "Invoice"."InvoiceId"="InvoiceLine"."InvoiceId" inner join "Track" on "Track"."TrackId"="InvoiceLine"."TrackId" inner join "Customer" on "Customer"."CustomerId"="Invoice"."CustomerId" where "Country"='Austria' and "GenreId" in (1,3) group by "Invoice"."CustomerId" having sum("InvoiceLine"."UnitPrice"*"Quantity")>20 )update "Invoice"set "Total"="Total"*0.8from discountwhere "Invoice"."CustomerId"=discount."CustomerId"

Sommario
In questo suggerimento abbiamo visto le differenze di sintassi per le istruzioni UPDATE quando si usa una JOIN in SQL Server, Oracle e PostgreSQL.
Passi successivi
- Ci sono altri modi di aggiornare con le JOIN in Oracle, in particolare usando la clausolaWHERE EXISTS con le subquery. Ma è simile a ciò che è stato ottenuto usando la sintassi che ho impiegato nel mio esempio di codice.
- Si prega di notare che ho usato SSMS per SQL Server, SQL Developer per Oracle e PGAdmin per PostgreSQL. Tutti sono disponibili per il download gratuito.
Ultimo aggiornamento: 2021-01-04


Informazioni sull autore
 Andrea Gnemmi è un professionista di Database e Data Warehouse con quasi 20 anni di esperienza, avendo iniziato la sua carriera nell’amministrazione di database con SQL Server 2000.
Andrea Gnemmi è un professionista di Database e Data Warehouse con quasi 20 anni di esperienza, avendo iniziato la sua carriera nell’amministrazione di database con SQL Server 2000.Vedi tutti i miei consigli
- Altri consigli su SQL Server DBA…