La gemma nascosta di SQL Server: UPDATE from SELECT
3 semplici modi per usare UPDATE from SELECT rendendo il tuo lavoro più facile
Probabilmente ti sei già trovato in questa situazione: Avevate bisogno di aggiornare i dati di una tabella utilizzando le informazioni memorizzate in un’altra tabella. Spesso incontro persone che non hanno sentito parlare della potente soluzione UPDATE from SELECT che SQL Server fornisce per questo problema. Infatti, ho lottato con questo problema per un bel po’ di tempo prima di scoprire questa gemma.
Nelle righe seguenti, vi mostrerò tre trucchi che mi hanno reso la vita più semplice in molte occasioni. Per questo, abbiamo prima bisogno di due tabelle:

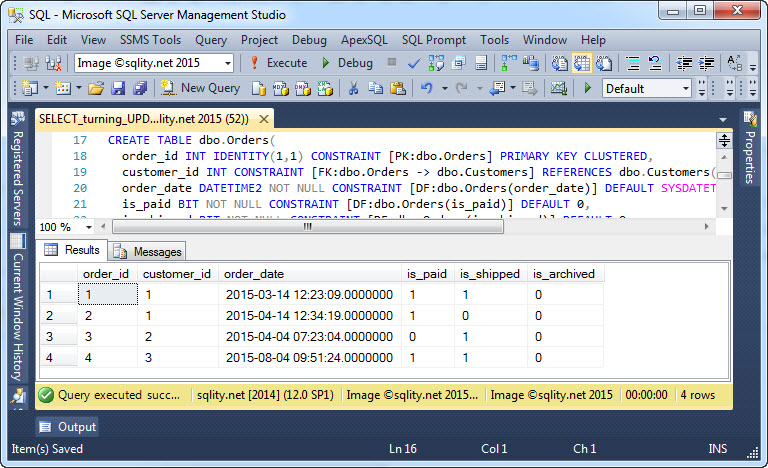
Se volete seguire, potete ottenere lo script qui: The Hidden SQL Server Gem – UPDATE from SELECT.sql
Sviluppa il tuo UPDATE da una SELECT
Ora che abbiamo l’ambiente impostato, immergiamoci in come farlo funzionare. Prima di mostrarvi la soluzione multitabella, lasciate che vi dimostri la forma più semplice della sintassi UPDATE FROM e vi mostri un semplice trucco per rendere lo sviluppo delle vostre dichiarazioni UPDATE davvero semplice, scrivendo prima una dichiarazione SELECT e poi trasformandola in un aggiornamento cancellando due caratteri. Intrigante?
La tabella dbo.Orders contiene una colonna is_archived. Questa è usata per archiviare gli ordini più vecchi di 90 giorni. Tuttavia, abbiamo la regola aggiuntiva che gli ordini che non sono stati ancora pagati o spediti non possono essere archiviati. (In questo esempio, la colonna is_archived non ha alcun effetto fisico. Vedere il mio articolo SQL Server Pro Using Table Partitions to Archive Old Data in OLTP Environments se siete interessati a come trasformare la colonna is_archived in un vero e proprio interruttore di archiviazione.)
Un’istruzione SELECT per restituire i record archiviabili sarebbe come questa:
FROM dbo.Orders AS O
WHERE O.order_date < DATEADD(DAY,-90,SYSDATETIME())
AND O.is_paid = 1
AND O.is_shipped = 1;
Ora aggiungiamo un po’ di magia:
SELECT *, — */
is_archived = 1
FROM dbo.Orders AS O
WHERE O.order_date < DATEADD(DAY,-90,SYSDATETIME())
E O.is_paid = 1
E O.is_shipped = 1;
Questa è ancora una semplice istruzione SELECT. Abbiamo solo aggiunto due commenti e una colonna aggiuntiva. Quella colonna aggiuntiva sta usando la non comune sintassi alias name = value con è equivalente alla più comune sintassi value AS name.
La bellezza di questo sta nel fatto che posso trasformare questa select in una dichiarazione UPDATE sintatticamente corretta, semplicemente rimuovendo i due trattini davanti alla parola chiave UPDATE:
SELECT *, — */
is_archived = 1
FROM dbo.Orders AS O
WHERE O.order_date < DATEADD(DAY,-90,SYSDATETIME())
E O.is_paid = 1
E O.is_shipped = 1;
Questo aggiorna la tabella dbo.Orders proprio come farebbe una dichiarazione UPDATE dbo.Orders SET…, perché la tabella dbo.Orders è alias O e l’UPDATE fa riferimento allo stesso alias O.
Aggiungendo una JOIN all’istruzione UPDATE
La domanda che ci ha portato qui è come possiamo usare i dati di una tabella per aggiornare un’altra tabella. Non sarebbe bello se potessimo semplicemente “JOIN”? Buone notizie: La sintassi di cui sopra ci permette di fare proprio questo.
Di recente è stata aggiunta una colonna order_count alla tabella dbo.Customers. Il nostro compito ora è quello di valorizzare correttamente quella colonna in base agli ordini effettivi che ogni cliente ha fatto. Cominciamo di nuovo scrivendo prima una select:
SELECT *, — */
order_count = OA.cnt
FROM dbo.Customers AS C
JOIN(
SELECT O.customer_id,
COUNT(1) cnt
FROM dbo.Orders AS O
GROUP BY O.customer_id
)OA
ON C.customer_id = OA.customer_id;
Una volta che l’istruzione SELECT restituisce i risultati corretti, è facile passare a UPDATE:
SELECT *, — */
order_count = OA.cnt
FROM dbo.Customers AS C
JOIN(
SELECT O.customer_id,
COUNT(1) cnt
FROM dbo.Orders AS O
GROUP BY O.customer_id
)OA
ON C.customer_id = OA.customer_id;
A causa dell’uso dell’alias C, SQL Server sa di aggiornare la tabella dbo.Customers mentre tira dentro le informazioni necessarie da altre tabelle referenziate nell’istruzione.
Usare UPDATE con una CTE
Se le CTE sono la vostra passione, potete anche fare un passo avanti con questo. Finché SQL Server può facilmente determinare cosa si intende aggiornare, si può effettivamente “UPDATE” una CTE direttamente usando una sintassi molto simile:
(
SELECT O.customer_id,
COUNT(1) cnt
FROM dbo.Orders AS O
GROUP BY O.customer_id
),
customer_order_counts AS
(
SELECT
C.customer_id,
C.name,
C.order_count,
OC.cnt new_order_cnt
FROM dbo.Customers AS C
JOIN order_counts AS OC
ON C.customer_id = OC.customer_id
)
UPDATE COC SET /*
SELECT *, — */
order_count = COC.new_order_cnt
FROM customer_order_counts AS COC;
L’unica cosa che non si può fare con nessuna delle dichiarazioni di cui sopra, è aggiornare i dati in due tabelle contemporaneamente.
Una parola di cautela
Questa sintassi ci fornisce un modo molto potente per scrivere istruzioni UPDATE che richiedono dati da più di una tabella. Tuttavia, fate attenzione a non scrivere codice che mostra un comportamento casuale. Date un’occhiata a questa istruzione UPDATE:
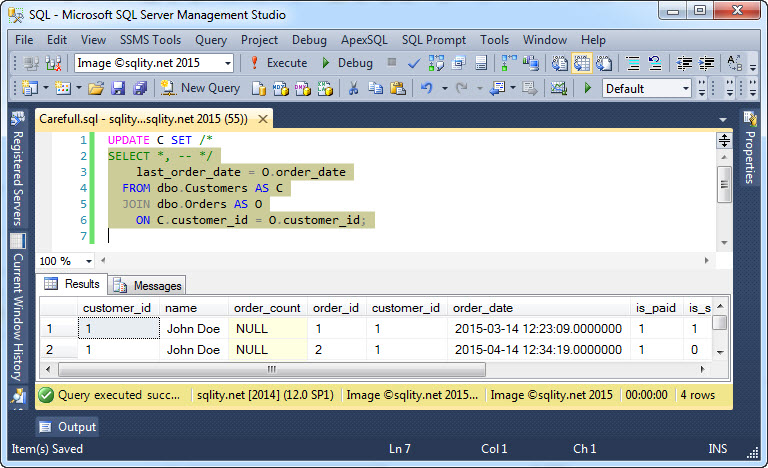
Proprio come la SELECT evidenziata restituisce un cliente con più ordini più volte, l’UPDATE aggiornerebbe felicemente ogni cliente più volte, ogni volta sovrascrivendo il cambiamento precedente. Solo l’ultima modifica persisterebbe.
Il problema con questo è che non c’è garanzia in quale ordine ciò avvenga. L’ordine dipende dal piano di esecuzione scelto e può cambiare in qualsiasi momento. Quindi, mentre la dichiarazione di cui sopra potrebbe effettivamente risultare nella scrittura dell’ultima data dell’ordine nei vostri test, probabilmente verrà eseguita in un ordine diverso una volta che la dichiarazione incontra una grande quantità di dati. Questo porterà a problemi difficili da debuggare, quindi fate attenzione a questa possibilità, quando scrivete le vostre dichiarazioni UPDATE FROM SELECT.