Selezionare il miglior algoritmo di Machine Learning per il tuo problema di regressione

Di recente ho iniziato una newsletterincentrata sui libri. Book Dives è una newsletter bisettimanale dove per ogni nuovo numero ci immergiamo in un libro di saggistica. Imparerai le lezioni principali del libro e come applicarle nella vita reale. Puoi iscriverti qui.
Quando ci si avvicina a qualsiasi tipo di problema di Machine Learning (ML) ci sono molti algoritmi diversi tra cui scegliere. Nell’apprendimento automatico, c’è qualcosa chiamato il teorema “No Free Lunch” che sostanzialmente afferma che nessun algoritmo di ML è il migliore per tutti i problemi. Le prestazioni dei diversi algoritmi di ML dipendono fortemente dalla dimensione e dalla struttura dei dati. Quindi, la scelta corretta dell’algoritmo spesso non è chiara, a meno che non testiamo direttamente i nostri algoritmi attraverso il vecchio e semplice trial and error.
Ma ci sono alcuni pro e contro per ogni algoritmo di ML che possiamo usare come guida. Anche se un algoritmo non sarà sempre migliore di un altro, ci sono alcune proprietà di ogni algoritmo che possiamo usare come guida per selezionare rapidamente quello corretto e sintonizzare gli iper parametri. Daremo un’occhiata ad alcuni importanti algoritmi di ML per problemi di regressione e fisseremo delle linee guida per quando usarli in base ai loro punti di forza e di debolezza. Questo post dovrebbe quindi servire come un grande aiuto per selezionare il miglior algoritmo di ML per il tuo problema di regressione!
Prima di iniziare, controlla la Newsletter AI Smart per leggere le ultime novità su AI, Machine Learning e Data Science!
Regressione lineare e polinomiale
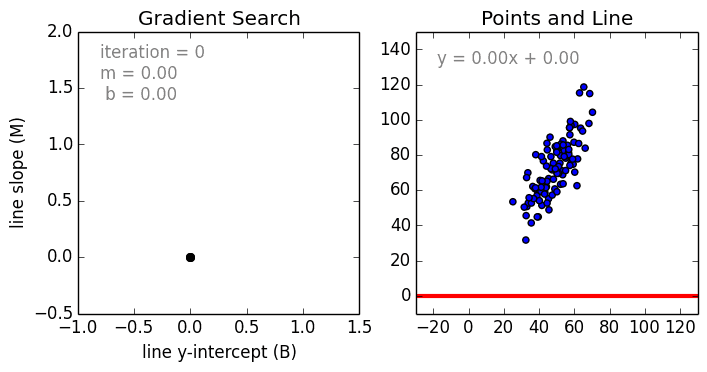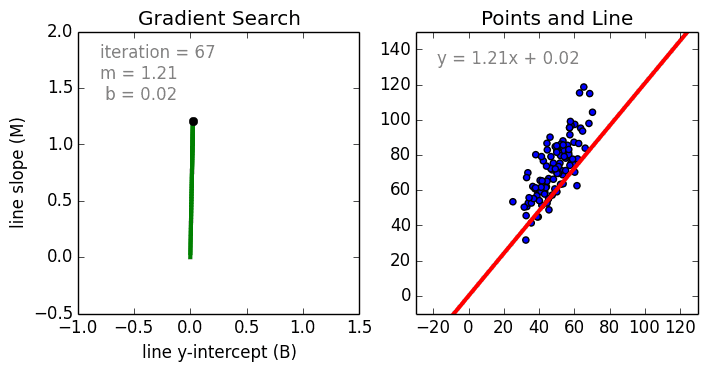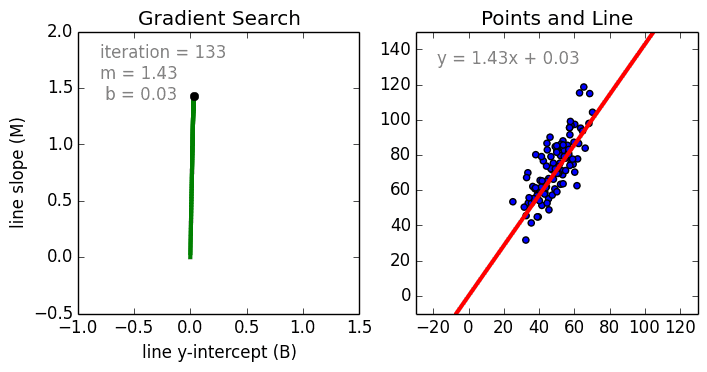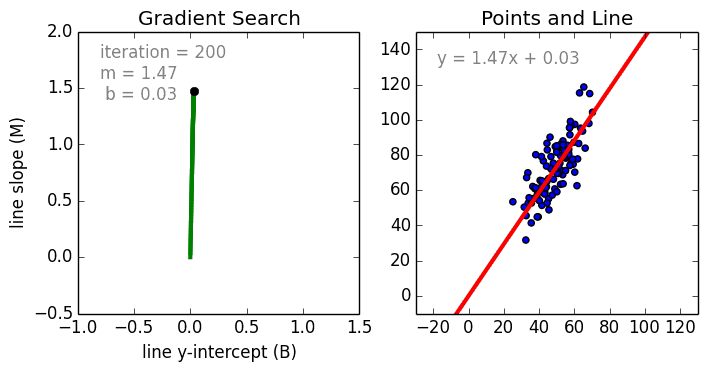
Partiamo dal caso semplice, La regressione lineare a singola variabile è una tecnica utilizzata per modellare la relazione tra una singola variabile indipendente in ingresso (variabile caratteristica) e una variabile dipendente in uscita utilizzando un modello lineare, cioè una linea.cioè una linea. Il caso più generale è la Regressione Lineare Multi Variabile dove viene creato un modello per la relazione tra più variabili di input indipendenti (variabili caratteristiche) e una variabile dipendente in uscita. Il modello rimane lineare in quanto l’output è una combinazione lineare delle variabili di input.
C’è un terzo caso più generale chiamato Regressione Polinomiale dove il modello ora diventa una combinazione non lineare delle variabili caratteristiche cioè ci possono essere variabili esponenziali, seno e coseno, ecc. Questo però richiede la conoscenza di come i dati si riferiscono all’output. I modelli di regressione possono essere addestrati usando Stochastic Gradient Descent (SGD).
Pros:
- Veloce da modellare ed è particolarmente utile quando la relazione da modellare non è estremamente complessa e se non si hanno molti dati.
- La regressione lineare è semplice da capire e può essere molto preziosa per le decisioni aziendali.
Cons:
- Per i dati non lineari, la regressione polinomiale può essere piuttosto impegnativa da progettare, poiché si devono avere alcune informazioni sulla struttura dei dati e sulle relazioni tra le variabili caratteristiche.
- Come risultato di quanto sopra, questi modelli non sono buoni come altri quando si tratta di dati altamente complessi.
Reti neurali
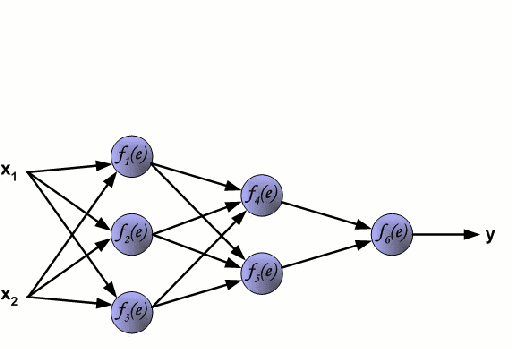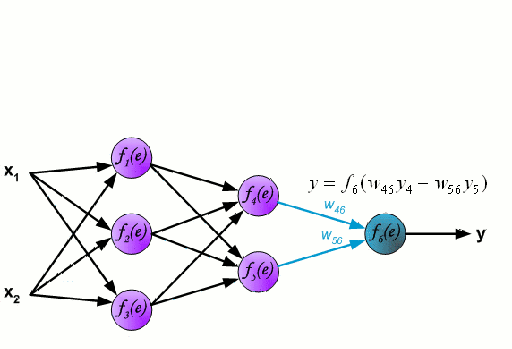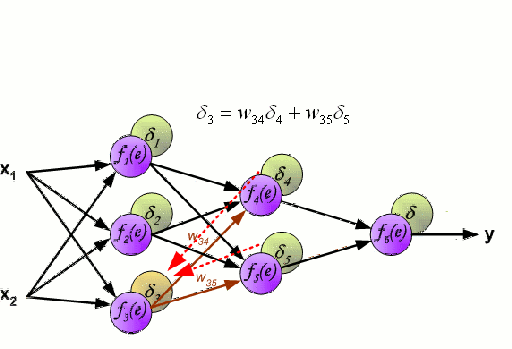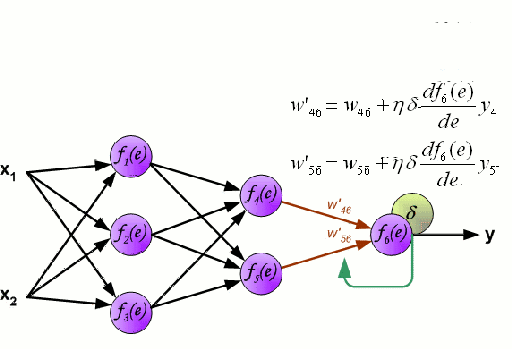
Una rete neurale consiste in un gruppo interconnesso di nodi chiamati neuroni. Le variabili caratteristiche in ingresso dai dati sono passate a questi neuroni come una combinazione lineare di più variabili, dove i valori moltiplicati per ogni variabile caratteristica sono noti come pesi. Una non-linearità viene poi applicata a questa combinazione lineare che dà alla rete neurale la capacità di modellare complesse relazioni non lineari. Una rete neurale può avere più strati in cui l’uscita di uno strato viene passata a quello successivo nello stesso modo. All’uscita, non c’è generalmente nessuna non-linearità applicata. Le reti neurali sono addestrate usando Stochastic Gradient Descent (SGD) e l’algoritmo di backpropagation (entrambi visualizzati nella GIF sopra).
Pros:
- Siccome le reti neurali possono avere molti strati (e quindi parametri) con non-linearità, sono molto efficaci nel modellare relazioni non lineari molto complesse.
- In genere non dobbiamo preoccuparci della struttura dei dati perché le reti neurali sono molto flessibili nell’apprendere quasi tutti i tipi di relazioni tra caratteristiche e variabili.
- La ricerca ha costantemente dimostrato che dare semplicemente alla rete più dati di allenamento, sia totalmente nuovi che provenienti dall’ampliamento del set di dati originale, porta benefici alle prestazioni della rete.
Cons:
- A causa della complessità di questi modelli, non sono facili da interpretare e comprendere.
- Possono essere piuttosto impegnativi e computazionalmente intensivi da addestrare, richiedendo un’attenta sintonizzazione degli iper-parametri e l’impostazione del programma del tasso di apprendimento.
- Richiedono molti dati per raggiungere alte prestazioni e sono generalmente superati da altri algoritmi di ML nei casi di “piccoli dati”.
Alberi di regressione e foreste casuali
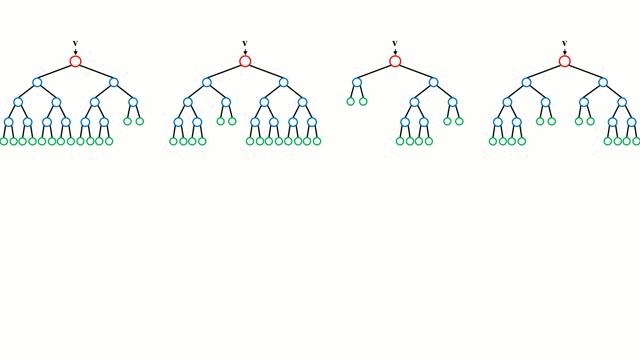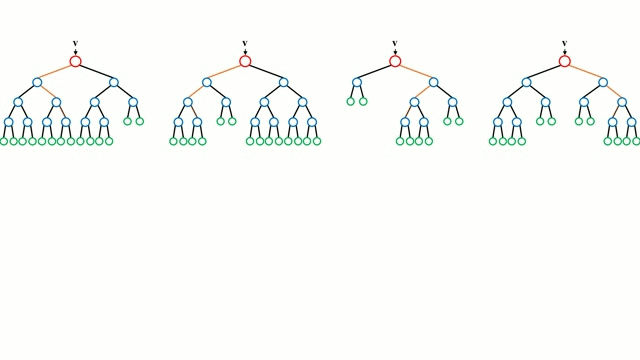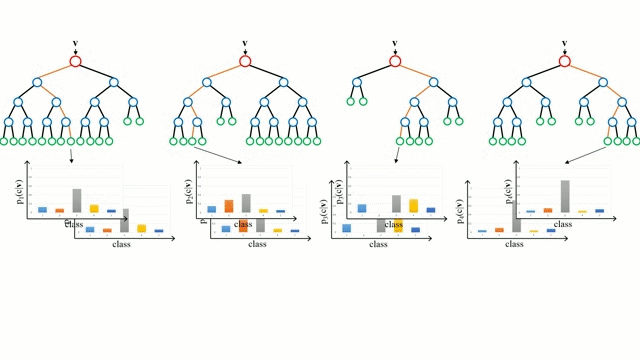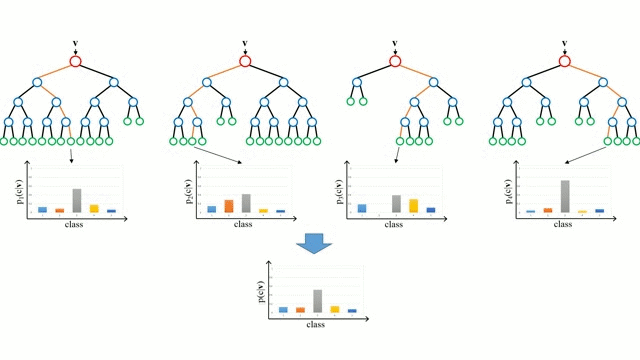
Partendo dal caso base, un albero di decisione è un modello intuitivo in cui si attraversa lungo i rami dell’albero e si seleziona il prossimo ramo da scendere in base a una decisione in un nodo. L’induzione dell’albero è il compito di prendere un insieme di istanze di addestramento come input, decidere quali attributi sono migliori per dividere, dividere il set di dati, e ripetere sui set di dati risultanti divisi fino a quando tutte le istanze di addestramento sono categorizzate. Durante la costruzione dell’albero, l’obiettivo è quello di dividere sugli attributi che creano i nodi figli più puri possibili, il che manterrebbe al minimo il numero di suddivisioni che dovrebbero essere fatte per classificare tutte le istanze nel nostro set di dati. La purezza è misurata dal concetto di guadagno di informazioni, che si riferisce a quanto dovrebbe essere noto su un’istanza non vista in precedenza per poterla classificare correttamente. In pratica, questo viene misurato confrontando l’entropia, o la quantità di informazioni necessarie per classificare una singola istanza di una partizione corrente del dataset, con la quantità di informazioni per classificare una singola istanza se la partizione corrente del dataset dovesse essere ulteriormente partizionata su un dato attributo.
Le foreste casuali sono semplicemente un insieme di alberi decisionali. Il vettore di input viene eseguito attraverso più alberi decisionali. Per la regressione, il valore di uscita di tutti gli alberi viene mediato; per la classificazione viene usato uno schema di voto per determinare la classe finale.
Pros:
- Grande nell’apprendimento di relazioni complesse e altamente non lineari. Di solito possono raggiungere prestazioni piuttosto elevate, meglio della regressione polinomiale e spesso alla pari con le reti neurali.
- Molto facile da interpretare e capire. Anche se il modello finale addestrato può imparare relazioni complesse, i confini decisionali che sono costruiti durante l’addestramento sono facili e pratici da capire.
Cons:
- A causa della natura dell’addestramento degli alberi decisionali possono essere inclini ad un grande overfitting. Un modello di albero decisionale completato può essere eccessivamente complesso e contenere strutture non necessarie. Anche se questo a volte può essere alleviato usando una corretta potatura degli alberi e insiemi di foreste casuali più grandi.
- L’uso di insiemi di foreste casuali più grandi per ottenere prestazioni più elevate comporta l’inconveniente di essere più lenti e di richiedere più memoria.
Conclusione
Boom! Ecco i pro e i contro! Nel prossimo post daremo un’occhiata ai pro e ai contro dei diversi modelli di classificazione. Spero che questo post ti sia piaciuto e che tu abbia imparato qualcosa di nuovo e utile. Se l’hai fatto, sentiti libero di fare qualche applauso.