How To Find Elements in Selenium WebDriver?
WebElements は、アプリケーションのテストにおいて重要な役割を果たします。 まず最初にすべきことは、Web ページ上でこれらの要素を見つけることです。
- なぜ FindElement や FindElements が必要なのか
- FindElement と FindElements の違い
- ロケータ戦略/ ロケータの種類
- 要素の配列の中で要素を見つけるには?
Selenium WebDriverでのFind Elements。 なぜ Find Element または FindElements が必要なのか
Selenium は Web サイトの自動データ読み込みとリグレッション テストに使用されます。
Find Element コマンドは、Web ページ内の Web 要素を一意に識別するために使用されます。
Find Element コマンドは、Web ページ内の Web 要素 (1 つ) を一意に識別するために使用されます。一方、Find Elements コマンドは、Web ページ内の Web 要素のリストを一意に識別するために使用されます。
Selenium WebDriver での Find Elements。 FindElement “と “FindElements “の違い
|
Find Element |
Find 要素 |
| 複数のウェブ要素がロケータによって発見された場合、最初に一致するウェブ要素を返します |
一致するウェブ要素のリストを返します。 |
| 要素が見つからない場合は NoSuchElementException をスローします |
マッチする要素が見つからない場合は空のリストを返します。 found |
| このメソッドは、ユニークなウェブ要素を検出するためにのみ使用されます |
このメソッドは、マッチする要素のコレクションを返すために使用されます。 |
ID、Name、Class Name、Link Text、Partial Link Text、Tag Name、XPATHなど、Webページ内のWeb要素/エレメントを一意に識別する方法は複数あります。
Selenium WebDriverで要素を見つける。 ロケーターストラテジー/ロケーターの種類
ロケーターストラテジーは、要素やFindElementsを見つけるために以下のタイプのいずれかになります –
- ID
- Name
- ClassName
- TagName
- Link Text/Partial Link Text
- CSS Selector
- XPATH Selector
ここで、これらのストラテジーが要素の検索にどのように使用できるかを見てみましょう。 まず、要素の検索について見てみましょう
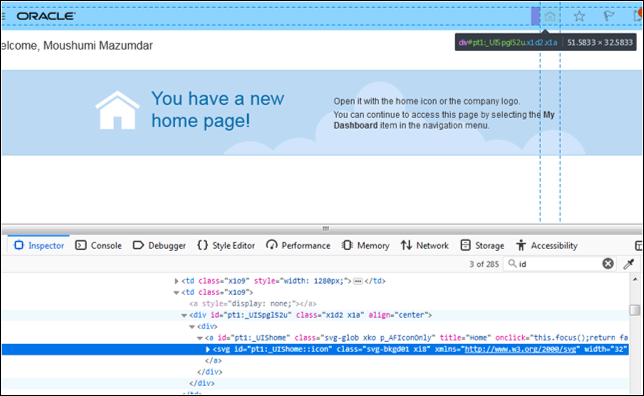
IDによる検索
IDは各要素に固有のものなので、IDロケーターを使用して要素を検索する一般的な方法です。 これは、要素を検出する最も一般的な最速かつ安全な方法です。
ウェブサイトに一意でないIDや動的に生成されたIDがある場合、この戦略は要素を一意に見つけるためには使用できませんが、代わりにロケータに一致する最初のウェブ要素が返されます。
Syntax:
public class LocateByID{public static void main (String args){// Open browserWebDriver driver = new FirefoxDriver();//instance of Chrome | Firefox | IE driverdriver.get(<url>);// Open ApplicationWebElement elm = driver.findElement(By.id("pt1:_UIShome::icon"));// will raise NoSuchElementException if not foundelm.click()//e.g- click the element}}
では、名前を使用して要素を検索する方法を理解しましょう。
名前で検索
この方法は、ドライバーが「id」属性の代わりに「name」属性で要素を検索しようとすることを除いて、「Idで検索」に似ています。
Syntax:
public class LocateByName{public static void main (String args){// Open browserWebDriver driver = new FirefoxDriver();//instance of Chrome | Firefox | IE driverdriver.get(<url>);// Open ApplicationWebElement elm = driver.findElement(By.name("name"));// will raise NoSuchElementException if not foundelm.sendKeys("Hi");//e.g - type Hi in the detected field}}
さて、先に進み、classNameを使用してSeleniumで要素を見つける方法を理解しましょう。
Find by ClassName
このメソッドはCLASS属性の値に基づいて要素を見つけます。
Syntax:
driver.findElements(By.className(<locator_value>)) ;//要素のリストの場合
or
driver.findElement(By.className(<locator_value>)) ;//単一のウェブ要素の場合
public class LocateByClass {public static void main (String args){// Open browserWebDriver driver = new FirefoxDriver();//instance of Chrome | Firefox | IE driverdriver.get(<url>);// Open ApplicationList<WebElement> links = driver.findElements(By.className("svg-bkgd01 xi8"));//return an empty list if elements not foun// loop over the list and perform the logic of a single element}}
さて、SeleniumでTagNameを使って要素を見つける方法を理解しましょう。
タグ名で探す
この方法は、要素のHTMLタグ名に基づいて要素を見つけます。 これはあまり使われておらず、特定の Web 要素が Id/name/link/className/XPATH/CSS で検出できない場合の最終手段として使用されます。
Syntax:
driver.findElement(By.tagName(<locator_value>)) ;//単一のウェブ要素
or
driver.findElements(By.tagName(<locator_value>)) ;//要素のリストの場合
public class LocateByTagName{public static void main (String args){// Open browserWebDriver driver = new FirefoxDriver();//instance of Chrome | Firefox | IE driverdriver.get(<url>);// Open ApplicationWebElement ul = driver.findElement(By.id(<id>));List<WebElement> links = ul.findElements(By.tagName("li"));...}}
Image- Selenium – Locating Web Elements on Page- Edureka
以上、TagNameを使った要素の探し方についてでした。 ここからは、リンクテキストを使った要素の探し方を見ていきましょう
TextFind by Link Text/Partial Link
この方法では、aタグ(Link)の要素を、リンク名またはリンク名の一部が一致している状態で見つけることができます。
Syntax
driver.findElement(By.linkText(<link_text>)) ;//単一のウェブ要素
or
driver.findElements(By.linkText(<link_text>)) ;//要素のリストの場合
driver.findElement(By.partialLinkText(<link_text>)) ;//単一のウェブ要素
or
driver.findElements(By.partialLinkText(<link_text>)) ;//要素のリストの場合
これはSeleniumでLinkTextを使って要素を見つける方法についてです。
CSSセレクタによる検索
ADFベースのアプリケーションのように動的なIDを生成するWebサイトや、IDや名前を生成しないReact jsのような最新のjavascriptフレームワークで構築されたWebサイトでは、要素を検索するためにID/Name戦略によるロケータを使用できません。
パフォーマンスのために XPath セレクタではなく CSS セレクタを選択するというのは、現在では伝説となっています。 ハイブリッドなアプローチを選択することもできます。
CSS セレクタはブラウザのネイティブ サポートがあるため、場合によっては XPATH セレクタよりも高速になることがあります。
XPATHSelector
XPATH は標準的な XML クエリ構文を使用しているため、より読みやすく、学習曲線も急ではありませんが、CSS セレクタは、XPATH とは異なり、よりシンプルな構文をサポートしていますが、XPATH のような標準的なものではなく、その他のドキュメント サポートもありません。
主に使用されるCSSセレクタのフォーマットを以下に示します。
- タグと
- ID
- タグとClass
- タグとAttribute
- タグ、Class, and Attribute
- 副文字列のマッチ
- Starts With (^)
- Ends With ($)
- Contains (*)
- 子要素
- 直接の子
- 副子
- nth-?子
以下のスクリーンショットを参照 –
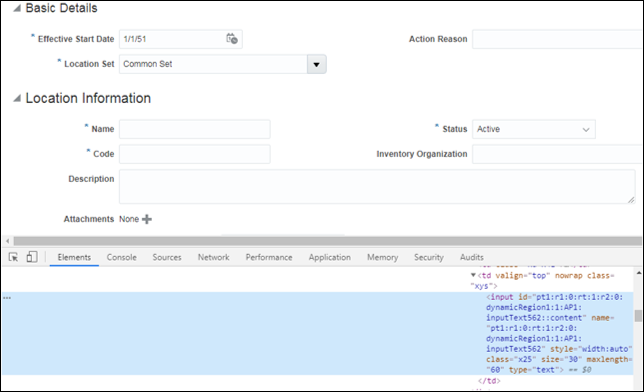
ID付きタグ
css= タグ # id
public class LocateByCSSSelector{ public static void main (String args){ WebDriver driver = new FirefoxDriver();//instance of Chrome | Firefox | IE driver driver.get(<url>);// Open ApplicationWebElement el = driver.findElement(By.cssSelector("input#pt1:r1:0:rt:1:r2:0:dynamicRegion1:1:AP1:inputText562::content"));el.sendKeys("Location1");}}
タグとクラス
css = tag.class public static void main (String args){ WebDriver driver = new FirefoxDriver();//instance of Chrome | Firefox | IE driver driver.get(<url>);// Open ApplicationWebElement el = driver.findElement(By.cssSelector("input.x25"));el.sendKeys("Location1"); }}
タグと属性
css = tagpublic class LocateByCSSSelector{ public static void main (String args){ WebDriver driver = new FirefoxDriver();//instance of Chrome | Firefox | IE driver driver.get(<url>);// Open ApplicationWebElement el = driver.findElement(By.cssSelector("input"));el.sendKeys("Location1"); }}
タグ, クラスを使用しています。 and attribute
css = tag.classpublic class LocateByCSSSelector{ public static void main (String args){ WebDriver driver = new FirefoxDriver();//instance of Chrome | Firefox | IE driver driver.get(<url>);// Open ApplicationWebElement el = driver.findElement(By.cssSelector("input.x25"));el.sendKeys("Location1"); }}
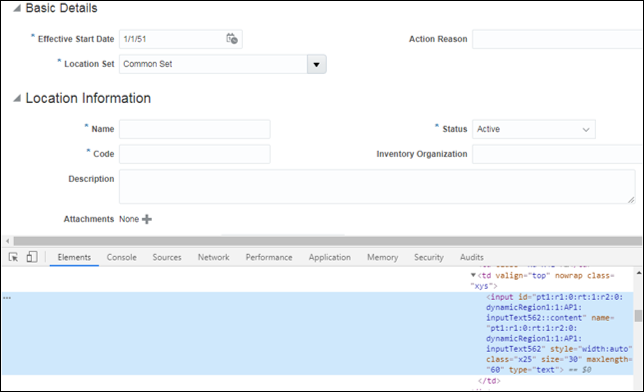
サブストリングのマッチ
Starts with –
public class LocateByCSSSelector{public static void main (String args){WebDriver driver = new FirefoxDriver(); //instance of Chrome | Firefox | IE driverdriver.get(<url>); // Open ApplicationWebElement el = driver.findElement(By.cssSelector("input"));el.sendKeys("Location1");}}
Ends with –
<span style="font-weight: 400"></span>public class LocateByCSSSelector{ public static void main (String args){ WebDriver driver = new FirefoxDriver();//instance of Chrome | Firefox | IE driver driver.get(<url>);// Open ApplicationWebElement el = driver.findElement(By.cssSelector("input"));el.sendKeys("Location1"); }}
上記のスクリーンショットと同じ例を参照してください。
Contains
public class LocateByCSSSelector{ public static void main (String args){ WebDriver driver = new FirefoxDriver();//instance of Chrome | Firefox | IE driver driver.get(<url>);// Open ApplicationWebElement el = driver.findElement(By.cssSelector("input"));el.sendKeys("Location1"); }}
別に上記の構文は以下のように書くことができます –
public class LocateByCSSSelector{ public static void main (String args){//instance of Chrome | Firefox | IE driver WebDriver driver = new FirefoxDriver();driver.get(<url>);// Open ApplicationWebElement el = driver.findElement(By.cssSelector("input:contains('AP1')]"));el.sendKeys("Location1"); }}
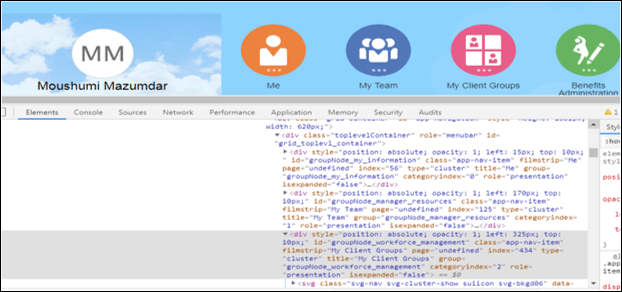
子要素の配置(直接の子/サブの子)
構文。
parentLocator>childLocator
public class LocateByCSSSelector
{
public static void main (String args)
{
WebDriver driver = new FirefoxDriver();//Chrome|Firefox|IEのドライバのインスタンス
driver.get(<url>);//アプリケーションを開く
WebElement el = driver.findElement(By.cssSelector(“div#grid_toplevl_container > div#groupNode_workforce_management”));
el.click() をクリックします。
}
}
- サブの子
- ロケータが直接の子/サブの子になることができるだけで、先ほどと同じです
- 番目の子
- nth-of-の使用
- iv class=”0タイプを使用する
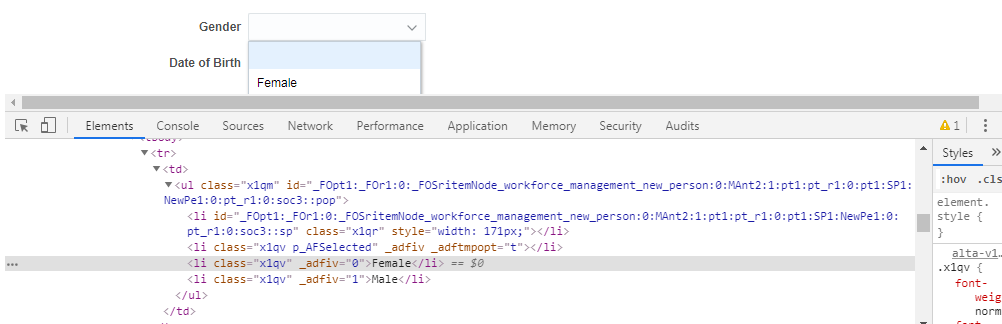
上記のliドロップダウンから「Female」を検出する場合
public class LocateByCSSSelector{ public static void main (String args){ WebDriver driver = new FirefoxDriver();//instance of Chrome | Firefox | IE driver driver.get(<url>);// Open ApplicationWebElement el = driver.findElement(By.cssSelector("ul#_FO... li:nth-of-type(2)"));el.click(); }}
XPATHセレクタで検索する
テスト自動化コードでは、一般的にid, 一般的には、id、name、classなどのロケータを使用することが多いです。 これらの種類のロケータを使用するのが一般的です。 しかし、時には、DOMでそれらのどれも見つけることができず、また、いくつかの要素のロケータがDOMで動的に変更されることもあります。 このような状況では、スマートなロケータを使用する必要があります。
最近、Oracle Fusion SaaS 画面のリグレッション テストの自動化に取り組んでいたとき、Web 要素の位置を特定する方法に苦労しました。
最近、Oracle Fusion SaaS画面のリグレッション・テストの自動化に取り組んでいたとき、Web要素の位置を特定する方法に悩んでいました。さまざまな環境で同じバージョンのSaaSインスタンスが異なるIDを生成していたのですが、XPATHセレクタが私の助けとなり、主にcontains()オプションを使用してWeb要素を探しました。
絶対的な XPATH と相対的な XPATH
| アブソリュート | リラティブ | |
| 要素の位置を特定する直接的な方法 | ||
| DOM要素の中央から開始します | ||
| 要素へのアクセス経路が位置によって変化すると壊れてしまう可能性があります | DOMに対する相対的な検索なので比較的安定しています。 | |
| “/”で始まり、ルートから始まる | “//”で始まり、ルートから始まる | 。 |
| 長いXPATH表現 | 短い表現 |
//tagpublic class LocateByXPATHSel{ public static void main (String args){ WebDriver driver = new FirefoxDriver();//instance of Chrome | Firefox | IE driver driver.get(<url>);// Open ApplicationWebElement el = driver.findElement(By.xpath("xpath=//button")); // trying to locate a butttonel.click(); }}
Using contains()
これは非常に便利なXPath Selenium locatorで、時にはテスト自動化エンジニアの命を救ってくれます。 要素の属性が動的な場合、ウェブ要素の定数部分にcontains()を使用することができますが、必要に応じて任意の条件でcontains()を使用することもできます。
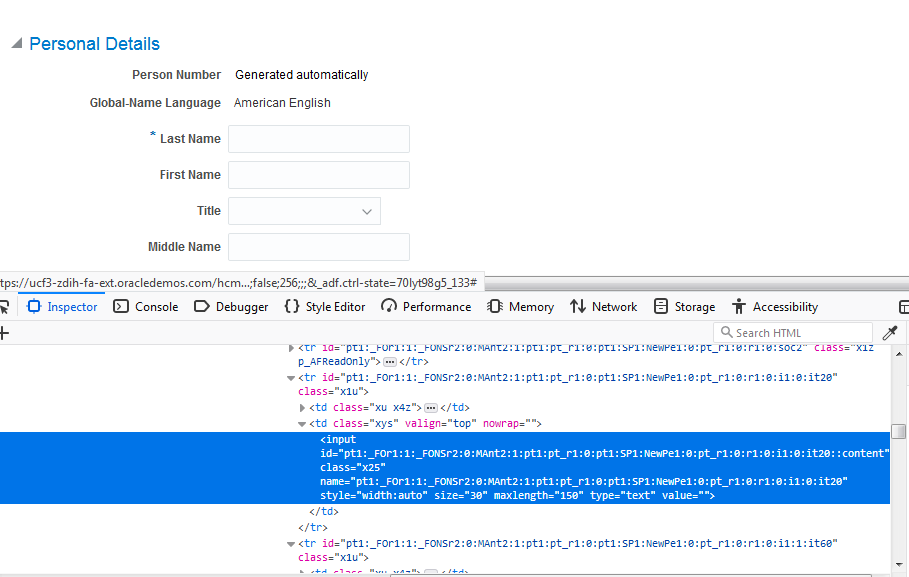
Fusion Instance#1
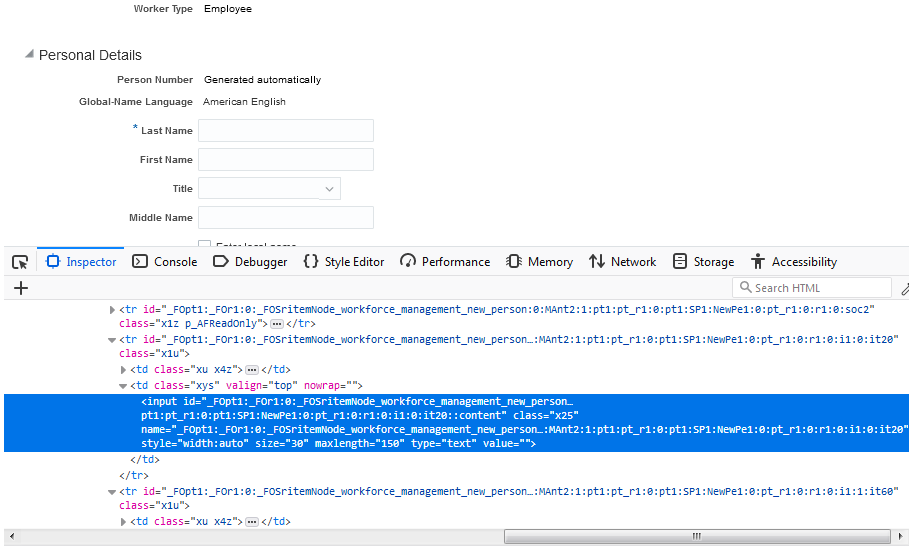
Fusion Instance#2
p Edureka
同じフィールドを比較すると、2つの動的に生成されたIDがあります –
//input
and
//input
このケースでは、動的なWeb要素の定数部分を特定する必要があります。1:pt1:pt_r1:0:pt1:SP1:NewPe1:0:pt_r1:0:r1:0:i1:0:it20::content” であり、以下のように XPATH 構文を作成します:
xpath=//input で、同じ selenium recording が両方のインスタンスで動作するようにします。
public class LocateByXPATHSel{
public static void main (String args){
WebDriver driver = new FirefoxDriver();//Chrome|Firefox|IEドライバのインスタンス
driver.get(<url>);// アプリケーションを開く
WebElement el = driver.findElement(By.xpath(“xpath=//input “));
el.sendKeys(“Johnson”);
}
}
Starts-with
このメソッドは、属性の開始テキストをチェックします。 属性の値が動的に変化するときに使うと便利ですが、変化しない属性の値にもこのメソッドを使うことができます。
Syntax:
//tag
Example:
//input
連鎖した宣言
複数の相対的なXPath宣言を”//”のダブルスラッシュで連鎖させることで、以下のように要素の位置を検索することができます。
xpath=//div//a
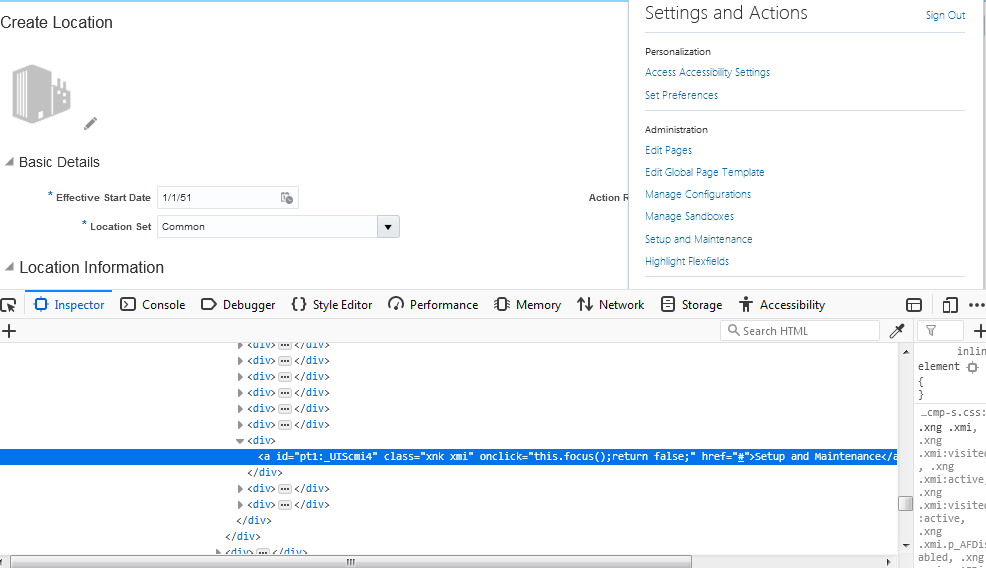
‘and’ ‘or’ 演算子の組み合わせ
上記の同じスクリーンショットを参照して、以下のように条件を書くことができます –
xpath=//a
xpath=//a
Ancestor
このオプションを使用して、特定のWeb要素の祖先の助けを借りてWeb要素を見つけることができます。
Following-sibling
コンテキストノードの次の兄弟を選択します。
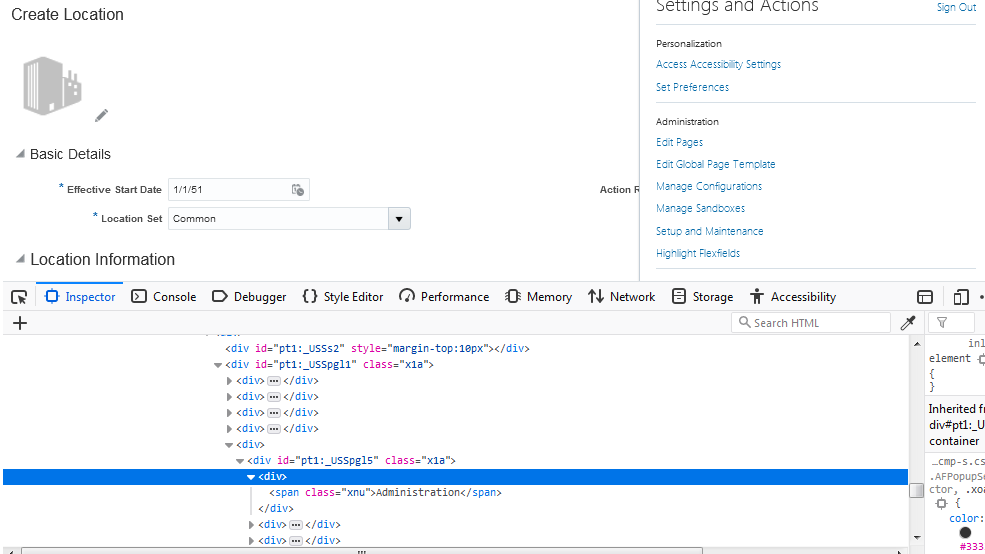
例を示します。
//span/ancestor::div/following-sibling::div
上記の例では、「管理」の下にあるすべてのメニューにアクセスしようとしています。
以下のように、与えられた親ノードの後にある要素の検索を開始します。 次の文の前にある要素を見つけてトップノードとして設定し、そのノードの後にあるすべての要素を探し始めます。
Syntax:
//tagName//following::tagName
Example:
/div//following::input
つまり、基本的にはid=’xx’のdivから検索を開始し、divタグに続くtagname =’input’の要素をすべて検索します。
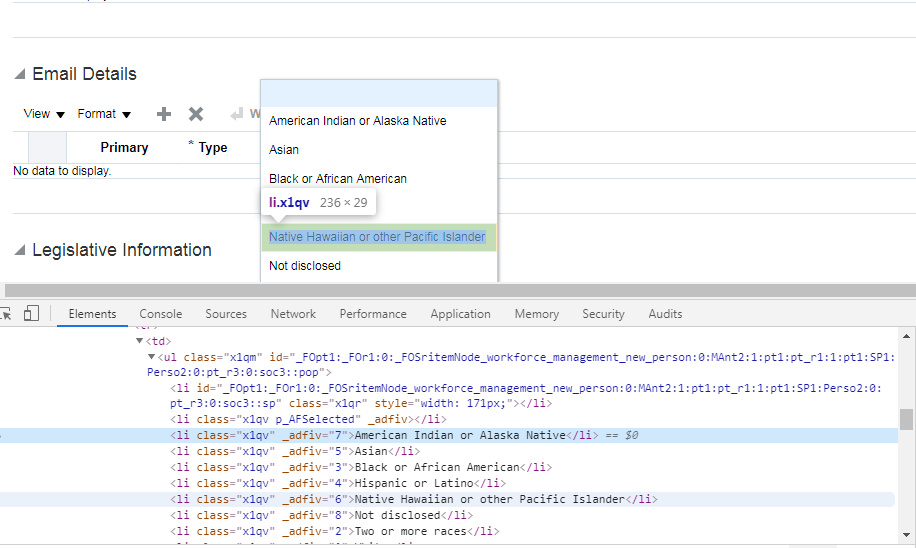
Child
現在のノードのすべての子要素を選択します。
次のシナリオですべての’li’要素を取得するには、次のように構文を記述します – //ul/child:li
Preceding
現在のノードの前にあるすべてのノードを選択します。
Syntax:
//tagName//preceeding::tagName
Selenium WebDriverで要素を探す。
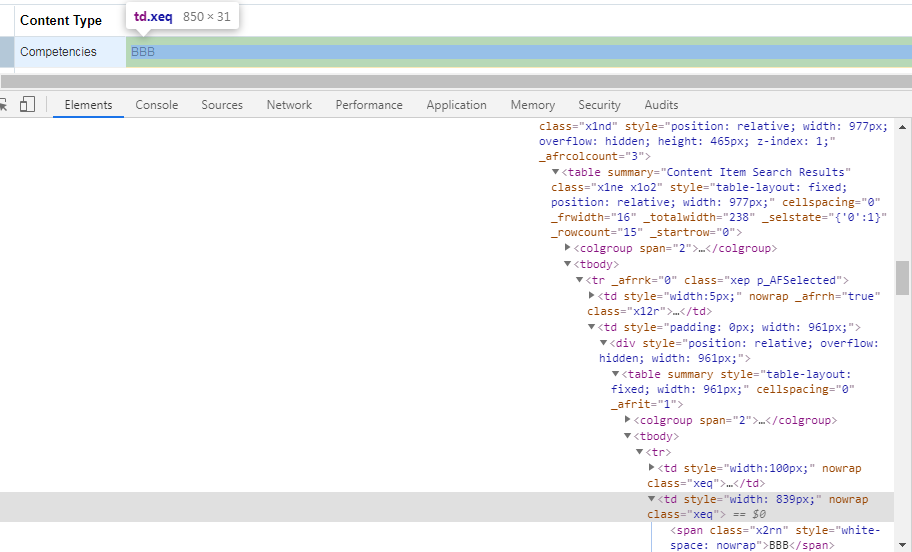
Example:
/div/table/tbody/tr/td/div/table/tbody/tr/td
配列の位置を利用して、配列のi番目の要素にアクセスすることができます。
これで、ウェブページ上で要素を見つけるために使用されるさまざまなセレクタや戦略をほぼ網羅することができました。
もしあなたが Selenium を学び、テスト分野でキャリアを築きたいのであれば、ここにあるインタラクティブなライブオンラインの Selenium 認定トレーニングをチェックしてください。