SQL Update Statement met Join in SQL Server vs Oracle vs PostgreSQL
Door: Andrea Gnemmi | Bijgewerkt: 2021-01-04 | Comments | Related: Meer > Andere Database Platforms
Probleem
Zoals de meeste DBA’s en ontwikkelaars die zowel met SQL Server als Oracle werken al weten, zijn er enkele verschillen in hoe je rijen bijwerkt met behulp van een join tussen SQL Server en Oracle. Met name is dit niet mogelijk met Oracle zonder enige finesse. PostgreSQL heeft een vergelijkbare ANSI SQL aanpak als SQL Server. In dit artikel vergelijken we hoe je updates uitvoert als je een join gebruikt tussen SQL Server, Oracle en PostgreSQL.
Oplossing
Hieronder zullen we een vergelijking maken van de verschillende syntaxis die gebruikt wordt om gegevens bij te werken als je een join gebruikt.
Een opmerking over de terminologie: in Oracle hebben we geen database met de naam Chinook,maar een schema of beter gezegd een User. In Oracle, tenzij je Pluggable Databases gebruikt, kun je slechts één database per instantie hebben.
Voor testdoeleinden zal ik het gratis te downloaden databasemonster Chinook gebruiken, omdat het in meerdere RDBMS-formaten beschikbaar is. Het is een simulatie van een digitale media winkel met enkele voorbeeldgegevens. Het enige wat je hoeft te doen is de versie te downloaden die je nodig hebt en de scripts uit te voeren voor de datastructuur en het invoegen van de data.
SQL Server Update Statement with Join
We beginnen met een snelle herinnering van hoe een SQL UPDATE statement met een JOIN werkt in SQL Server.
Normaal gesproken werken we een rij of meerdere rijen in een tabel bij met een filter op basis van eenWHEREclausule. We controleren op een fout en vinden dat er geen stad als Vienne bestaat. Maar wel Wien in het Duits of Wenen in het Engels:
select customerid, FirstName,LastName, Address, city,countryfrom dbo.Customerwhere city='Vienne'

We kunnen dit corrigeren met een normaal UPDATE statement, zoals:
update dbo.Customerset city='Wien'where city='Vienne'

We kunnen de factuurtabel ook bijwerken op basis van een klant. Laten we eerst de gegevens met een eenvoudige SELECT-query controleren:
select invoice.BillingCityfrom invoiceinner join customer on invoice.CustomerId=customer.CustomerIdwhere customer.City='Vienne'
We hebben dit resultaat:
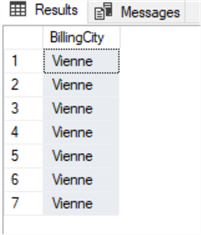
Op dit punt kunnen we een UPDATE uitvoeren met dezelfde JOIN-clausule als de SELECT-query die we zojuist hebben uitgevoerd. Ik weet dat we een eenvoudige UPDATE naar de ene tabel hadden kunnen gebruiken, maar dit voorbeeld laat alleen zien hoe het kan worden gedaan als we een JOIN doen:
update invoiceset invoice.BillingCity='Wien'from invoiceinner join customeron invoice.CustomerId=customer.CustomerIdwhere customer.City='Vienne'

We kunnen zelfs een CTE (Common Table Expression) in de JOIN-clausule gebruiken om een bepaald filter te gebruiken.
Voorbeeld: Stel dat we een speciale korting op de totale factuur willen geven aan Oostenrijkse klanten die meer dan 20 dollar hebben uitgegeven aan Rock en Metal (genre 1 en 3). De subset is eenvoudig te extraheren met de volgende query:
select Invoice.CustomerId,sum(invoiceline.UnitPrice*Quantity) as genretotalfrom invoiceinner join InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceIdinner join Track on Track.TrackId=InvoiceLine.TrackIdinner join customer on customer.CustomerId=Invoice.CustomerIdwhere country='Austria' and GenreId in (1,3)group by Invoice.CustomerIdhaving sum(invoiceline.UnitPrice*Quantity)>20
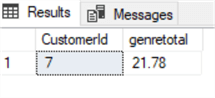
Voorstellend dat we een korting van 20% willen toepassen. We kunnen deze toepassen door de totale factuurtabel bij te werken op basis van de bovenstaande query met de onderstaande CTE:
; with discount as( select Invoice.CustomerId, sum(invoiceline.UnitPrice*Quantity) as genretotal from invoice inner join InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceId inner join Track on Track.TrackId=InvoiceLine.TrackId inner join customer on customer.CustomerId=Invoice.CustomerId where country='Austria' and GenreId in (1,3) group by Invoice.CustomerId having sum(invoiceline.UnitPrice*Quantity)>20)update Invoiceset total=total*0.8from Invoiceinner join discount on Invoice.CustomerId=discount.CustomerId
Oracle Update Statement with Join
Hoe werkt dit in Oracle? Het antwoord is vrij eenvoudig: in Oracle wordt deze syntaxis van eenUPDATE -statement met een JOIN niet ondersteund.
We moeten wat shortcuts uitvoeren om iets soortgelijks te kunnen doen. We kunnen gebruik maken van een subquery en een IN filter. We kunnen bijvoorbeeld de eerste UPDATE transformeren met de JOIN die we in SQL Server hebben gebruikt.
Laten we eerst eens met dezelfde SELECT query de gegevens van de Invoice tabel in Oracle controleren:
select invoice.BillingCityfrom chinook.invoiceinner join chinook.customer on invoice.CustomerId=customer.CustomerIdwhere customer.City='Vienne';
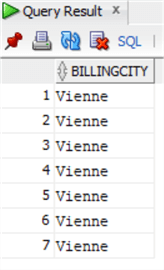
We transformeren het UPDATE-statement met de bovenstaande query als subquery, maar we extraheren de primaire sleutel Invoiceid om de update uit te voeren:
update chinook.invoiceset invoice.BillingCity='Wien'where invoiceid in ( select invoiceid from chinook.invoice inner join chinook.customer on invoice.CustomerId=customer.CustomerId where customer.City='Vienne' );
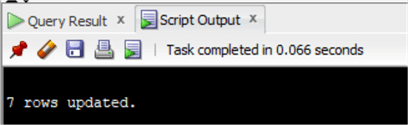
Niet vergeten vast te leggen. Aangezien we in Oracle werken, is er standaard geen auto commit:
commit;
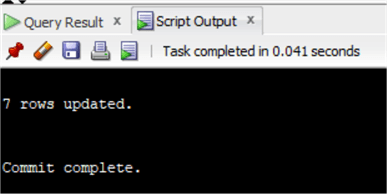
Dat was vrij eenvoudig, maar stel dat we een UPDATE moeten uitvoeren op basis van een andere grote tabel en de waarde in de andere tabel moeten gebruiken.
Voorstel dat we dezelfde UPDATE willen uitvoeren als we met de CTE op SQL Server hebben gedaan, dan kunnen we het JOIN-probleem met deze code oplossen:
update ( select invoice.customerid,total from chinook.Invoice inner join ( select Invoice.Cust merId as customerid_sub, sum(invoiceline.UnitPrice*Quantity) as genretotal from chinook.invoice inner join chinook.InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceId inner join chinook.Track on Track.TrackId=InvoiceLine.TrackId inner join chinook.customer on customer.CustomerId=Invoice.CustomerId where country='Austria' and GenreId in (1,3) group by Invoice.CustomerId having sum(invoiceline.UnitPrice*Quantity)>20 ) on Invoice.CustomerId=Customerid_sub )set total=total*0.8;
commit;
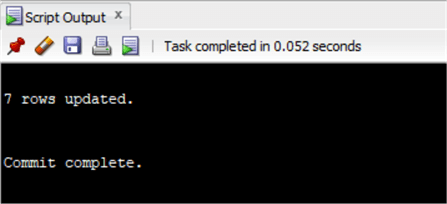
Zoals je misschien hebt gemerkt, heb ik de CTE in een subquery omgezet en deze samengevoegd met de tabel Factuur, vergelijkbaar met de update die met SQL Server is gedaan. Maar deze keer is het een select statement met de primaire sleutel en het totaal dat we willen bijwerken. Ik heb dit resultaat ingevoerd als de tabel om bij te werken. Het is een workaround, maar het werkt! Het enige waar je op moet letten is dat de resultaten uniek zijn en dat je niet meer rijen probeert te updaten dan je nodig hebt. Daarom doe ik altijd eerst een aselect om te controleren hoeveel rijen er moeten worden bijgewerkt.
Er is een elegantere oplossing, die gebruik maakt van het MERGE statement. De syntaxis is vergelijkbaar met die van MERGE in SQL Server, dus we gebruiken dezelfde UPDATE als in het vorige voorbeeld. Dit moet als volgt worden geschreven:
MERGE INTO chinook.InvoiceUSING ( select Invoice.CustomerId as customerid_sub, sum(invoiceline.UnitPrice*Quantity) as genretotal from chinook.invoice inner join chinook.InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceId inner join chinook.Track on Track.TrackId=InvoiceLine.TrackId inner join chinook.customer on customer.CustomerId=Invoice.CustomerId where country='Austria' and GenreId in (1,3) group by Invoice.CustomerId having sum(invoiceline.UnitPrice*Quantity)>20 ) ON (Invoice.CustomerId=Customerid_sub)WHEN MATCHED THENUPDATE set total=total*0.8;
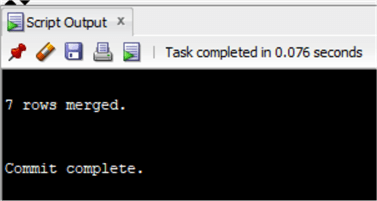
Zoals je kunt zien, is het leesbaarder dan de vorige oplossing. In SQL Server is de prestatie van MERGE statements niet altijd optimaal. Houd dit in gedachten bij het gebruik en test het voordat u het in een productieomgeving gebruikt.
PostgreSQL Update Statement met Join
Hoe zit het met PostgreSQL? In dit geval werken dezelfde concepten die in SQL Server worden gebruikt ook in PostgreSQL. We hebben slechts een paar verschillen met de syntax, omdat we de join niet specificeren. Maar we gebruiken de oude join syntaxis met de WHEREclause.
Laten we dezelfde SQL-code aanpassen die we in SQL Server hebben gebruikt en deze testen op de Chinook-database op PostgreSQL:
update "Invoice"set "BillingCity"='Wien'from "Customer"where "Invoice"."CustomerId"="Customer"."CustomerId"and "Customer"."City"='Vienne'
In dit geval hoeven we de eerste tabel waarop we de update gaan uitvoeren niet op te geven. De rest is precies hetzelfde als in SQL Server.
Laten we de code eens testen met de CTE (merk op dat we in PostgreSQL alle kolomnamen die met een hoofdletter zijn aangemaakt tussen aanhalingstekens moeten zetten, anders herkent het programma ze niet!):
; with discount as( select "Invoice"."CustomerId", sum("InvoiceLine"."UnitPrice"*"Quantity") as genretotal from "Invoice" inner join "InvoiceLine" on "Invoice"."InvoiceId"="InvoiceLine"."InvoiceId" inner join "Track" on "Track"."TrackId"="InvoiceLine"."TrackId" inner join "Customer" on "Customer"."CustomerId"="Invoice"."CustomerId" where "Country"='Austria' and "GenreId" in (1,3) group by "Invoice"."CustomerId" having sum("InvoiceLine"."UnitPrice"*"Quantity")>20 )update "Invoice"set "Total"="Total"*0.8from discountwhere "Invoice"."CustomerId"=discount."CustomerId"

Samenvatting
In deze tip hebben we de syntax verschillen gezien voor UPDATE statements bij het gebruik van een JOIN in SQL Server, Oracle en PostgreSQL.
Volgende stappen
- Er zijn andere manieren om bij te werken met joins in Oracle, met name door gebruik te maken van deWHERE EXISTS clause met subqueries. Maar het is vergelijkbaar met wat ik heb bereikt met de syntax die ik in mijn codevoorbeeld heb gebruikt.
- Merk op dat ik gebruik heb gemaakt van SSMS voor SQL Server, SQL Developer voor Oracle en PGAdmin voor PostgreSQL. Allen zijn gratis te downloaden.
Laatst Bijgewerkt: 2021-01-04


Over de auteur
 Andrea Gnemmi is een Database en Data Warehouse professional met bijna 20 jaar ervaring, en is zijn carrière begonnen in Database Administratie met SQL Server 2000.
Andrea Gnemmi is een Database en Data Warehouse professional met bijna 20 jaar ervaring, en is zijn carrière begonnen in Database Administratie met SQL Server 2000.Bekijk al mijn tips
- Meer SQL Server DBA Tips…