SQL Update Statement with Join in SQL Server vs Oracle vs PostgreSQL
By: Andrea Gnemmi | Updated: 2021-01-04 | Komentarze | Powiązane: Więcej > Inne platformy bazodanowe
Problem
Jak większość DBA’s i deweloperów, którzy pracują zarówno z SQL Server i Oracle już wiedzą, istnieją pewne różnice w sposobie aktualizacji wierszy przy użyciu joinbetween SQL Server i Oracle. W szczególności, nie jest to możliwe w Oracle bez pewnej finezji. PostgreSQL ma podobne podejście do ANSI SQL jak SQL Server. W tym artykule porównamy jak wykonać aktualizacje przy użyciu join pomiędzy SQL Server, Oracle oraz PostgreSQL.
Rozwiązanie
Poniżej porównamy różne składnie używane do aktualizacji danych przy użyciu join.
Uwaga dotycząca terminologii: w Oracle nie będziemy mieli bazy danych o nazwie Chinook, ale schemat lub bardziej poprawnie User. W Oracle, o ile nie używasz Pluggable Databases, możesz mieć tylko jedną bazę danych na instancję.
Do celów testowych użyję darmowej próbki bazy danych Chinook, ponieważ jest ona dostępna w wielu formatach RDBMS. Jest to symulacja sklepu z mediami cyfrowymi z przykładowymi danymi. Wystarczy pobrać wersję, którą potrzebujesz i uruchomić skrypty struktury danych oraz wstawiania danych.
SQL Server Update Statement with Join
Zaczniemy od szybkiego przypomnienia, jak działa instrukcja SQL UPDATE z JOIN w SQL Server.
Normalnie aktualizujemy wiersz lub wiele wierszy w tabeli za pomocą filtra opartego na klauzuliWHERE. Sprawdzamy błąd i okazuje się, że nie ma takiego miasta jak Vienne. Ale raczej Wien po niemiecku lub Wiedeń po angielsku:
select customerid, FirstName,LastName, Address, city,countryfrom dbo.Customerwhere city='Vienne'

Możemy to poprawić za pomocą normalnej instrukcji UPDATE, takiej jak:
update dbo.Customerset city='Wien'where city='Vienne'

Możemy również zaktualizować tabelę faktur na podstawie klienta. Najpierw sprawdźmy dane za pomocą prostego zapytania SELECT:
select invoice.BillingCityfrom invoiceinner join customer on invoice.CustomerId=customer.CustomerIdwhere customer.City='Vienne'
Mamy taki wynik:
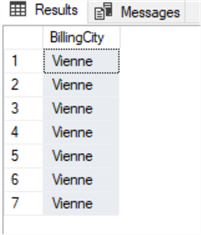
W tym momencie możemy wykonać UPDATE używając tej samej klauzuli JOIN co zapytanie SELECT, które właśnie wykonaliśmy. Wiem, że mogliśmy użyć prostego UPDATE do jednej tabeli, ale ten przykład tylko pokazuje, jak można to zrobić podczas wykonywania JOIN:
update invoiceset invoice.BillingCity='Wien'from invoiceinner join customeron invoice.CustomerId=customer.CustomerIdwhere customer.City='Vienne'

Możemy nawet użyć CTE (Common Table Expression) w klauzuli JOIN, aby mieć jakiś konkretny filtr.
Na przykład, załóżmy, że musimy dać specjalny rabat na łączną kwotę faktury dla austriackich klientów, którzy wydali więcej niż 20 dolarów na Rock i Metal (gatunek 1 i 3). Podzbiór ten można łatwo wyodrębnić za pomocą następującego zapytania:
select Invoice.CustomerId,sum(invoiceline.UnitPrice*Quantity) as genretotalfrom invoiceinner join InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceIdinner join Track on Track.TrackId=InvoiceLine.TrackIdinner join customer on customer.CustomerId=Invoice.CustomerIdwhere country='Austria' and GenreId in (1,3)group by Invoice.CustomerIdhaving sum(invoiceline.UnitPrice*Quantity)>20
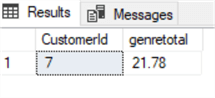
Załóżmy, że chcemy udzielić rabatu w wysokości 20%. Możemy go zastosować aktualizując tabelę faktur całkowitych na podstawie powyższego zapytania za pomocą poniższego CTE:
; with discount as( select Invoice.CustomerId, sum(invoiceline.UnitPrice*Quantity) as genretotal from invoice inner join InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceId inner join Track on Track.TrackId=InvoiceLine.TrackId inner join customer on customer.CustomerId=Invoice.CustomerId where country='Austria' and GenreId in (1,3) group by Invoice.CustomerId having sum(invoiceline.UnitPrice*Quantity)>20)update Invoiceset total=total*0.8from Invoiceinner join discount on Invoice.CustomerId=discount.CustomerId
Oracle Update Statement with Join
Jak to działa w Oracle? Odpowiedź jest dość prosta: w Oracle nie jest obsługiwana składniaUPDATE statementwith a JOIN.
Musimy dokonać pewnych skrótów, aby zrobić coś podobnego. Możemy skorzystać z podzapytania i filtra IN. Na przykład, możemy przekształcić pierwszy UPDATE za pomocą JOIN, którego używaliśmy w SQL Server.
Na początek sprawdźmy za pomocą tego samego zapytania SELECT dane tabeli Invoice w Oracle:
select invoice.BillingCityfrom chinook.invoiceinner join chinook.customer on invoice.CustomerId=customer.CustomerIdwhere customer.City='Vienne';
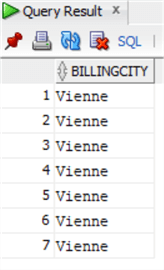
Przekształcimy instrukcję UPDATE używając powyższego zapytania jako podzapytania, ale wyodrębnimy klucz główny Invoiceid w celu wykonania aktualizacji:
update chinook.invoiceset invoice.BillingCity='Wien'where invoiceid in ( select invoiceid from chinook.invoice inner join chinook.customer on invoice.CustomerId=customer.CustomerId where customer.City='Vienne' );
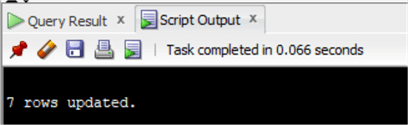
Nie zapomnij o commit. Ponieważ jesteśmy w Oracle, nie ma domyślnie auto commit:
commit;
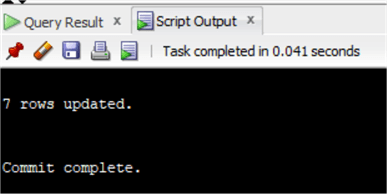
To było dość proste, ale załóżmy, że potrzebujemy UPDATE opartego na innej dużej tabeli i użyć wartości w innej tabeli.
Założywszy, że chcielibyśmy wykonać ten sam UPDATE, który wykonaliśmy za pomocą CTE na SQL Server, możemy pokonać problem JOIN za pomocą tego kodu:
update ( select invoice.customerid,total from chinook.Invoice inner join ( select Invoice.Cust merId as customerid_sub, sum(invoiceline.UnitPrice*Quantity) as genretotal from chinook.invoice inner join chinook.InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceId inner join chinook.Track on Track.TrackId=InvoiceLine.TrackId inner join chinook.customer on customer.CustomerId=Invoice.CustomerId where country='Austria' and GenreId in (1,3) group by Invoice.CustomerId having sum(invoiceline.UnitPrice*Quantity)>20 ) on Invoice.CustomerId=Customerid_sub )set total=total*0.8;
commit;
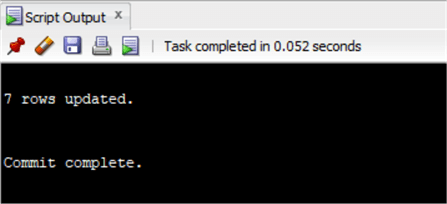
Jak pewnie zauważyłeś, przekształciłem CTE w podzapytanie i połączyłem je z tabelą Invoice podobnie do aktualizacji wykonanej w SQL Server. Jednak tym razem jest to instrukcja select z kluczem głównym i sumą, którą chcemy zaktualizować. Wprowadziłem ten wynik jako tabelę do aktualizacji. Jest to obejście, ale działa! Jedyną rzeczą, na którą musisz uważać, jest zapewnienie, że wyniki są unikalne i nie próbujesz aktualizować więcej wierszy niż te, których potrzebujesz. Dlatego też zawsze wykonuję aselect przed sprawdzeniem ile wierszy powinno zostać zaktualizowanych.
Istnieje bardziej eleganckie rozwiązanie, wykorzystujące instrukcję MERGE. Składnia jest podobna do MERGE w SQL Server, więc użyjemy tego samego UPDATE co w ostatnim przykładzie.Powinno to być napisane tak:
MERGE INTO chinook.InvoiceUSING ( select Invoice.CustomerId as customerid_sub, sum(invoiceline.UnitPrice*Quantity) as genretotal from chinook.invoice inner join chinook.InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceId inner join chinook.Track on Track.TrackId=InvoiceLine.TrackId inner join chinook.customer on customer.CustomerId=Invoice.CustomerId where country='Austria' and GenreId in (1,3) group by Invoice.CustomerId having sum(invoiceline.UnitPrice*Quantity)>20 ) ON (Invoice.CustomerId=Customerid_sub)WHEN MATCHED THENUPDATE set total=total*0.8;
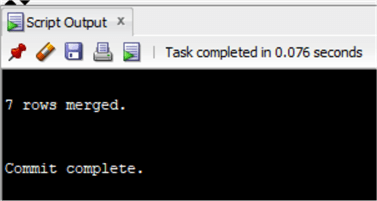
Jak widać, jest to bardziej czytelne niż poprzednie rozwiązanie. W SQL Server wydajność instrukcji MERGE nie zawsze jest najlepsza. Należy o tym pamiętać i przetestować je przed użyciem w środowisku produkcyjnym.
PostgreSQL Update Statement with Join
A co z PostgreSQL? W tym przypadku, te same koncepcje, które działają w SQL Server, działają również w PostgreSQL. Mamy tylko kilka różnic w składni, ponieważ nie określamy złączenia. Używamy za to starej składni złączenia z klauzulą WHERE.
Zaadaptujmy ten sam kod SQL, którego używaliśmy na SQL Server i przetestujmy go na bazie danych Chinook na PostgreSQL:
update "Invoice"set "BillingCity"='Wien'from "Customer"where "Invoice"."CustomerId"="Customer"."CustomerId"and "Customer"."City"='Vienne'
W tym przypadku nie musimy określać pierwszej tabeli, na której będziemy wykonywaćupdate. Reszta jest dokładnie taka sama jak w SQL Server.
Przetestujmy kod z CTE (proszę pamiętać, że w PostgreSQL musimy wszystkie nazwy kolumn, które zostały utworzone z dużej litery umieścić w cudzysłowie inaczej nie zostaną one rozpoznane!):
; with discount as( select "Invoice"."CustomerId", sum("InvoiceLine"."UnitPrice"*"Quantity") as genretotal from "Invoice" inner join "InvoiceLine" on "Invoice"."InvoiceId"="InvoiceLine"."InvoiceId" inner join "Track" on "Track"."TrackId"="InvoiceLine"."TrackId" inner join "Customer" on "Customer"."CustomerId"="Invoice"."CustomerId" where "Country"='Austria' and "GenreId" in (1,3) group by "Invoice"."CustomerId" having sum("InvoiceLine"."UnitPrice"*"Quantity")>20 )update "Invoice"set "Total"="Total"*0.8from discountwhere "Invoice"."CustomerId"=discount."CustomerId"

Podsumowanie
W tym poradniku poznaliśmy różnice w składni poleceń UPDATE przy użyciu JOIN w SQL Server, Oracle i PostgreSQL.
Kolejne kroki
- Istnieją inne sposoby aktualizacji za pomocą złączeń w Oracle, zwłaszcza przy użyciu klauzuliWHERE EXISTS z podzapytaniami. Jest to jednak podobne do tego, co zostało osiągnięte przy użyciu składni, którą zastosowałem w moim przykładzie kodu.
- Proszę zauważyć, że użyłem SSMS dla SQL Server, SQL Developer dla Oracle oraz PGAdmin dla PostgreSQL. Wszystkie są dostępne do pobrania bezpłatnie.
Ostatnia aktualizacja: 2021-01-04


O autorze Autor
 Andrea Gnemmi jest profesjonalistą w dziedzinie Baz Danych i Hurtowni Danych z prawie 20-letnim doświadczeniem, rozpoczął swoją karierę w Administracji Baz Danych z SQL Server 2000.
Andrea Gnemmi jest profesjonalistą w dziedzinie Baz Danych i Hurtowni Danych z prawie 20-letnim doświadczeniem, rozpoczął swoją karierę w Administracji Baz Danych z SQL Server 2000.Zobacz wszystkie moje wskazówki
- Więcej wskazówek SQL Server DBA…
.