Ukryty klejnot SQL Server: UPDATE from SELECT
3 Simple Ways to use UPDATE from SELECT making Your Job easier
Prawdopodobnie byłeś już kiedyś w takiej sytuacji: Potrzebowałeś zaktualizować dane w jednej tabeli, używając informacji przechowywanych w innej tabeli. Często spotykam ludzi, którzy nie słyszeli o potężnym rozwiązaniu UPDATE from SELECT, jakie SQL Server oferuje dla tego problemu. W rzeczywistości, zmagałem się z tym problemem przez dłuższy czas, zanim dowiedziałem się o tym klejnocie.
W kolejnych linijkach pokażę Ci trzy sztuczki, które uprościły moje życie przy wielu okazjach. W tym celu potrzebujemy najpierw dwóch tabel:

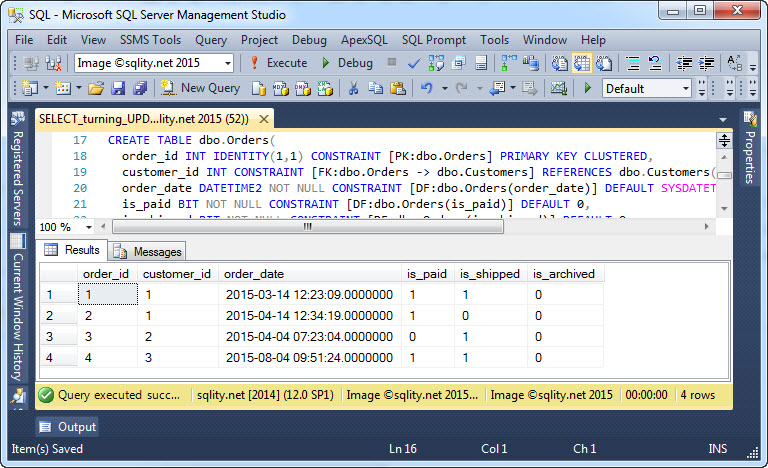
Jeśli chcesz śledzić, możesz pobrać skrypt tutaj: The Hidden SQL Server Gem – UPDATE from SELECT.sql
Rozwiń swój UPDATE from a SELECT
Teraz, gdy mamy już skonfigurowane środowisko, zanurkujmy w to, jak sprawić, by to działało. Zanim pokażę Ci rozwiązanie dla wielu tabel, pozwól, że zademonstruję najprostszą formę składni UPDATE FROM i pokażę Ci prostą sztuczkę, która sprawi, że tworzenie deklaracji UPDATE będzie naprawdę proste, poprzez napisanie najpierw instrukcji SELECT, a następnie przekształcenie jej w aktualizację poprzez usunięcie dwóch znaków. Zaintrygowany?
Tabela dbo.Orders zawiera kolumnę is_archived. Służy ona do archiwizacji zamówień starszych niż 90 dni. Mamy jednak dodatkową zasadę, że zamówienia, które nie zostały jeszcze opłacone lub wysłane nie mogą być archiwizowane. (W tym przykładzie kolumna is_archived nie ma fizycznego efektu. Zobacz mój artykuł SQL Server Pro Using Table Partitions to Archive Old Data in OLTP Environments, jeśli jesteś zainteresowany tym, jak przekształcić kolumnę is_archived w rzeczywisty przełącznik archiwizacji.)
Konstrukcja SELECT zwracająca rekordy nadające się do archiwizacji wyglądałaby następująco:
FROM dbo.Orders AS O
WHERE O.order_date < DATEADD(DAY,-90,SYSDATETIME())
AND O.is_paid = 1
AND O.is_shipped = 1;
Teraz dodajmy do tego trochę magii:
SELECT *, — */
is_archived = 1
FROM dbo.Orders AS O
WHERE O.order_date < DATEADD(DAY,-90,SYSDATETIME())
AND O.is_paid = 1
AND O.is_shipped = 1;
To wciąż jest prosta instrukcja SELECT. Dodaliśmy tylko dwa komentarze i dodatkową kolumnę. Ta dodatkowa kolumna używa niecodziennej składni aliasowej name = value z jest równoważna bardziej powszechnej składni value AS name.
Piękno tego polega na tym, że mogę zmienić ten select w poprawną składniowo instrukcję UPDATE, po prostu usuwając dwa myślniki przed słowem kluczowym UPDATE:
SELECT *, — */
is_archived = 1
FROM dbo.Orders AS O
WHERE O.order_date < DATEADD(DAY,-90,SYSDATETIME())
AND O.is_paid = 1
AND O.is_shipped = 1;
To aktualizuje tabelę dbo.Orders tak samo jak UPDATE dbo.Orders SET…, ponieważ tabela dbo.Orders ma alias O, a UPDATE odwołuje się do tego samego aliasu O.
Dodanie JOIN do instrukcji UPDATE
Pytanie, które nas tu przywiodło, dotyczyło tego, jak możemy użyć danych z jednej tabeli do aktualizacji innej tabeli. Czy nie byłoby miło, gdybyśmy mogli po prostu „JOIN”? Dobra wiadomość: Powyższa składnia pozwala nam właśnie na to.
Dawno temu do tabeli dbo.Customers została dodana kolumna order_count. Naszym zadaniem jest teraz poprawne wyliczenie wartości tej kolumny w oparciu o faktyczne zamówienia, które złożył każdy klient. Zaczynamy ponownie od napisania select first:
SELECT *, — */
order_count = OA.cnt
FROM dbo.Customers AS C
JOIN(
SELECT O.customer_id,
COUNT(1) cnt
FROM dbo.Orders AS O
GROUP BY O.customer_id
)OA
ON C.customer_id = OA.customer_id;
Gdy instrukcja SELECT zwróci prawidłowe wyniki, można łatwo zmienić ją na UPDATE:
SELECT *, — */
order_count = OA.cnt
FROM dbo.Customers AS C
JOIN(
SELECT O.customer_id,
COUNT(1) cnt
FROM dbo.Orders AS O
GROUP BY O.customer_id
)OA
ON C.customer_id = OA.customer_id;
Ponieważ dzięki użyciu aliasu C, SQL Server wie, że ma zaktualizować tabelę dbo.Customers, jednocześnie pobierając niezbędne informacje z innych tabel, do których odwołuje się instrukcja.
Używanie UPDATE z CTE
Jeśli CTE są Twoją rzeczą, możesz nawet pójść o krok dalej. Tak długo, jak SQL Server może łatwo określić, co zamierzasz zaktualizować, możesz faktycznie „UPDATE” CTE bezpośrednio używając bardzo podobnej składni:
(
SELECT O.customer_id,
COUNT(1) cnt
FROM dbo.Orders AS O
GROUP BY O.customer_id
),
customer_order_counts AS
(
SELECT
C.customer_id,
C.name,
C.order_count,
OC.cnt new_order_cnt
FROM dbo.Customers AS C
JOIN order_counts AS OC
ON C.customer_id = OC.customer_id
)
UPDATE COC SET /*
SELECT *, — */
order_count = COC.new_order_cnt
FROM customer_order_counts AS COC;
Jedyną rzeczą, której nie można zrobić za pomocą powyższych instrukcji, jest aktualizacja danych w dwóch tabelach jednocześnie.
Słowo przestrogi
Ta składnia zapewnia nam bardzo potężny sposób na pisanie poleceń UPDATE, które wymagają danych z więcej niż jednej tabeli. Należy jednak uważać, aby nie napisać kodu, który wykazuje przypadkowe zachowanie. Spójrzmy na poniższą instrukcję UPDATE:
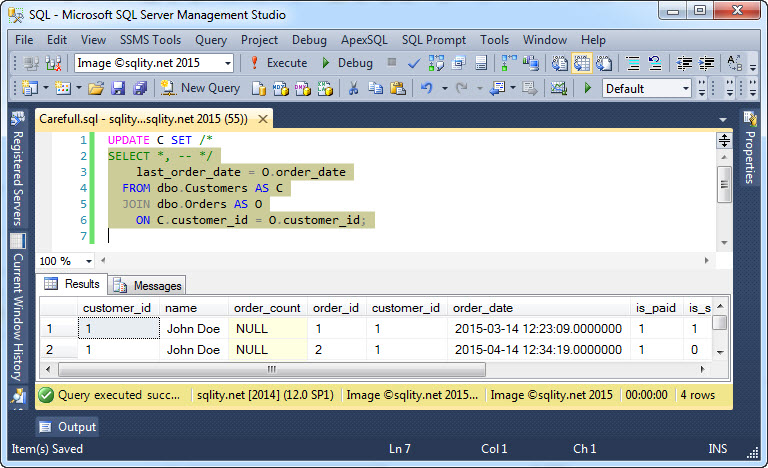
Tak jak zaznaczony SELECT zwraca klienta z wieloma zamówieniami wiele razy, UPDATE z radością zaktualizowałoby każdego klienta wiele razy, za każdym razem nadpisując poprzednią zmianę. Tylko ostatnia zmiana byłaby trwała.
Problem z tym jest taki, że nie ma gwarancji, w jakiej kolejności to się stanie. Kolejność zależy od wybranego planu wykonania i może się zmienić w dowolnym momencie. Tak więc, podczas gdy powyższe oświadczenie może faktycznie spowodować, że ostatnia data zamówienia zostanie zapisana w twoich testach, prawdopodobnie zostanie wykonana w innej kolejności, gdy oświadczenie napotka dużą ilość danych. Doprowadzi to do trudnych do debugowania problemów, więc zwróć uwagę na tę możliwość, podczas pisania swoich instrukcji UPDATE FROM SELECT.