RAID (matriz redundante de discos independentes)
RAID (matriz redundante de discos independentes) é uma forma de armazenar os mesmos dados em locais diferentes em vários discos rígidos ou unidades de estado sólido para proteger os dados em caso de falha de uma unidade. Existem diferentes níveis de RAID, contudo, e nem todos têm o objectivo de fornecer redundância.
Como funciona o RAID
RAID funciona colocando dados em múltiplos discos e permitindo que as operações de entrada/saída (E/S) se sobreponham de uma forma equilibrada, melhorando o desempenho. Como a utilização de múltiplos discos aumenta o tempo médio entre falhas (MTBF), o armazenamento de dados redundantemente também aumenta a tolerância a falhas.
As matrizes de RAID aparecem ao sistema operativo (SO) como uma única unidade lógica. RAID emprega as técnicas de espelhamento de disco ou striping de disco. O espelhamento copiará dados idênticos em mais do que uma unidade. A remoção de partições ajuda a espalhar os dados por várias unidades de disco. O espaço de armazenamento de cada unidade é dividido em unidades que vão desde um sector (512 bytes) até vários megabytes. As riscas de todos os discos são intercaladas e endereçadas por ordem.

EspelhoDisk e striping de disco também podem ser combinados numa matriz RAID.
Num sistema de utilizador único onde são armazenados registos grandes, as riscas são tipicamente configuradas para serem pequenas (talvez 512 bytes) de modo a que um único registo abranja todos os discos e possa ser acedido rapidamente lendo todos os discos ao mesmo tempo.
Num sistema multi-utilizador, um melhor desempenho requer uma banda suficientemente larga para manter o registo típico ou de tamanho máximo, permitindo a sobreposição de E/S de discos através de unidades.
controlador RAID
Um controlador RAID é um dispositivo utilizado para gerir unidades de disco rígido numa matriz de armazenamento. Pode ser utilizado como um nível de abstracção entre o SO e os discos físicos, apresentando grupos de discos como unidades lógicas. A utilização de um controlador RAID pode melhorar o desempenho e ajudar a proteger dados em caso de falha.
Um controlador RAID pode ser baseado em hardware ou software. Num produto RAID baseado em hardware, um controlador físico gere a matriz. O controlador também pode ser concebido para suportar formatos de unidade como SATA e SCSI. Um controlador RAID físico também pode ser incorporado na placa mãe de um servidor.
Com RAID baseado em software, o controlador utiliza os recursos do sistema de hardware, tais como o processador central e a memória. Embora desempenhe as mesmas funções que um controlador RAID baseado em hardware, os controladores RAID baseados em software podem não permitir um aumento tão grande do desempenho e podem afectar o desempenho de outras aplicações no servidor.
Se uma implementação RAID baseada em software não for compatível com o processo de arranque de um sistema, e os controladores RAID baseados em hardware forem demasiado caros, o firmware ou RAID baseado em driver é outra opção potencial.
Os chips controladores RAID baseados em hardware estão localizados na placa mãe, e todas as operações são executadas pela CPU, semelhante ao RAID baseado em software. Contudo, com o firmware, o sistema RAID só é implementado no início do processo de arranque. Uma vez carregado o SO, o controlador controlador assume a funcionalidade RAID. Um controlador RAID de firmware não é tão caro como uma opção de hardware, mas coloca mais pressão sobre o CPU do computador. O RAID baseado em firmware é também chamado RAID por software assistido por hardware, RAID de modelo híbrido e RAID falso.
Níveis de RAID
Dispositivos de RAID farão uso de diferentes versões, chamadas níveis. O papel original que cunhou o termo e desenvolveu o conceito de configuração RAID definiu seis níveis de RAID — 0 a 5. Este sistema numerado permitiu aos que estão em TI diferenciar as versões RAID. O número de níveis expandiu-se desde então e foi dividido em três categorias: níveis RAID padrão, aninhados e não-padrão.
Níveis RAID padrão
RAID 0. Esta configuração tem striping, mas sem redundância de dados. Oferece o melhor desempenho, mas não oferece tolerância a falhas.
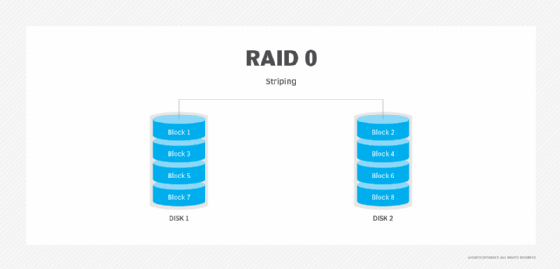
RAID 1. Também conhecida como espelhamento de disco, esta configuração consiste em pelo menos duas unidades que duplicam o armazenamento de dados. Não há striping. O desempenho de leitura é melhorado, uma vez que qualquer dos discos pode ser lido ao mesmo tempo. O desempenho de escrita é o mesmo que para o armazenamento de disco único.
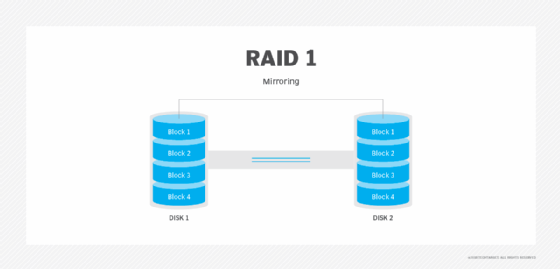
RAID 2. Esta configuração utiliza striping através de discos, com alguns discos a armazenarem informação de verificação e correcção de erros (ECC). RAID 2 também usa uma paridade de código Hamming dedicada; uma forma linear de código de correcção de erros. RAID 2 não tem vantagem sobre RAID 3 e já não é utilizado.
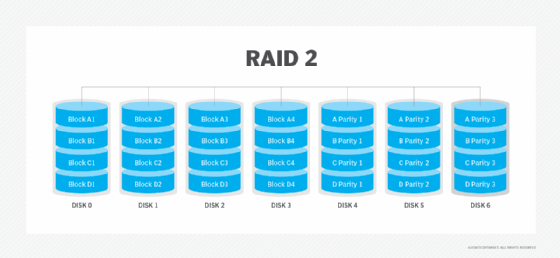
RAID 3. Esta técnica utiliza striping e dedica um disco ao armazenamento de informação de paridade. A informação ECC incorporada é utilizada para detectar erros. A recuperação de dados é realizada através do cálculo da informação exclusiva registada nas outras unidades. Uma vez que uma operação de E/S aborda todas as unidades ao mesmo tempo, o RAID 3 não pode sobrepor as E/S. Por esta razão, o RAID 3 é melhor para sistemas de utilizador único com aplicações de registo longo.
RAID 4. Este nível utiliza riscas grandes, o que significa que um utilizador pode ler registos de qualquer unidade. As E/S sobrepostas podem então ser utilizadas para operações de leitura. Uma vez que todas as operações de escrita são necessárias para actualizar a unidade de paridade, não é possível qualquer sobreposição de E/S.
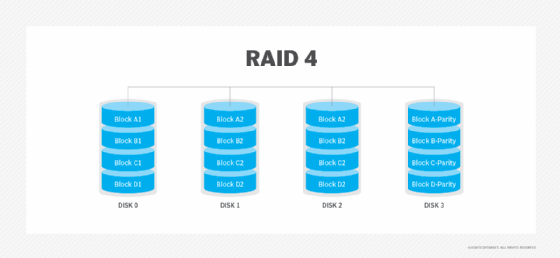
RAID 5. Este nível é baseado em faixas de nível de bloco de paridade. A informação da paridade é riscada em cada unidade, permitindo que a matriz funcione mesmo que uma unidade falhe. A arquitectura do array permite que operações de leitura e escrita abranjam múltiplas unidades – resultando num desempenho melhor do que o de uma única unidade, mas não tão elevado como o de um array RAID 0. RAID 5 requer pelo menos três discos, mas recomenda-se frequentemente a utilização de pelo menos cinco discos por razões de desempenho.
RAID 5 arrays são geralmente considerados como uma má escolha para utilização em sistemas de escrita intensiva devido ao impacto de desempenho associado à escrita de dados de paridade. Quando um disco falha, pode levar muito tempo a reconstruir uma matriz RAID 5.
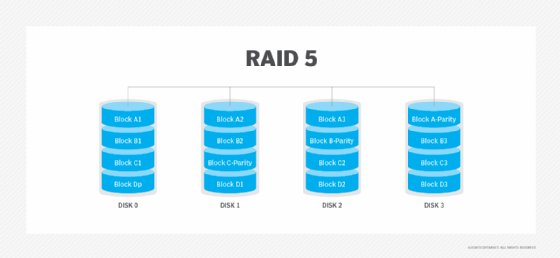
RAID 6. Esta técnica é semelhante ao RAID 5, mas inclui um segundo esquema de paridade distribuído pelas unidades da matriz. A utilização de paridade adicional permite que o array continue a funcionar mesmo que dois discos falhem simultaneamente. No entanto, esta protecção adicional tem um custo. As matrizes RAID 6 têm frequentemente um desempenho de escrita mais lento do que as matrizes RAID 5.
Níveis RAID aninhados
alguns níveis RAID são referidos como RAID aninhado porque se baseiam numa combinação de níveis RAID. Aqui estão alguns exemplos de níveis RAID aninhados.
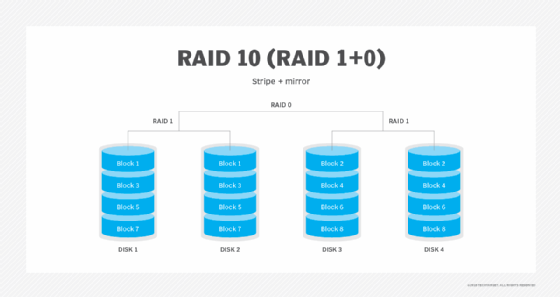
RAID 10 (RAID 1+0). Combinando RAID 1 e RAID 0, este nível é muitas vezes referido como RAID 10, que oferece um desempenho superior ao RAID 1, mas a um custo muito mais elevado. No RAID 1+0, os dados são espelhados e os espelhos são listrados.
RAID 01 (RAID 0+1). RAID 0+1 é semelhante ao RAID 1+0, excepto que o método de organização de dados é ligeiramente diferente. Em vez de criar um espelho e depois riscar o espelho, RAID 0+1 cria um conjunto de tiras e depois espelha o conjunto de tiras.
RAID 03 (RAID 0+3, também conhecido como RAID 53 ou RAID 5+3). Este nível utiliza striping (em estilo RAID 0) para os blocos de discos virtuais do RAID 3. Isto oferece um desempenho superior ao RAID 3, mas a um custo superior.
RAID 50 (RAID 5+0). Esta configuração combina paridade distribuída RAID 5 com striping RAID 0 para melhorar o desempenho RAID 5 sem reduzir a protecção de dados.
Níveis RAID não standard
Níveis RAID não standard variam dos níveis RAID standard e são geralmente desenvolvidos por empresas ou organizações para uso principalmente proprietário. Aqui estão alguns exemplos.
RAID 7. Um nível RAID não-padrão baseado em RAID 3 e RAID 4 que adiciona caching. Inclui um SO incorporado em tempo real como controlador, caching através de um autocarro de alta velocidade e outras características de um computador autónomo.
RAID adaptável. Este nível permite que o controlador RAID decida como armazenar a paridade em discos. Escolherá entre RAID 3 e RAID 5, dependendo do tipo de conjunto de RAID que melhor se comportará com o tipo de dados a serem escritos nos discos.
Linux MD RAID 10. Este nível, fornecido pelo kernel Linux, suporta a criação de matrizes RAID aninhadas e não padronizadas. O software RAID Linux também pode suportar a criação de configurações RAID padrão 0, RAID 1, RAID 4, RAID 5 e RAID 6.
Benefícios do RAID
Benefícios do RAID incluem o seguinte.
- Uma melhoria na relação custo-eficácia porque os discos de menor preço são utilizados em grande número.
- A utilização de vários discos rígidos permite ao RAID melhorar o desempenho de um único disco rígido.
- Velocidade e fiabilidade do computador após uma falha — dependendo da configuração.
- As leituras e gravações podem ser realizadas mais rapidamente do que com um único disco rígido com RAID 0. Isto porque um sistema de ficheiros é dividido e distribuído por unidades que trabalham em conjunto no mesmo ficheiro.
- Há uma maior disponibilidade e resiliência com RAID 5. Com o espelhamento, as matrizes RAID podem ter duas unidades contendo os mesmos dados, assegurando que uma continuará a funcionar se a outra falhar.
Downsides de usar RAID
RAID tem, no entanto, desvantagens. Alguns destes incluem:
- Níveis RAID aninhados são mais caros de implementar do que os níveis RAID tradicionais porque requerem um maior número de discos.
- O custo por gigabyte de dispositivos de armazenamento é maior para RAID aninhado porque muitas das unidades são utilizadas para redundância.
- Quando uma unidade falha, a probabilidade de outra unidade do array também falhar em breve aumenta, o que provavelmente resultaria na perda de dados. Isto porque todas as unidades num array RAID são instaladas ao mesmo tempo, pelo que todas as unidades estão sujeitas à mesma quantidade de desgaste.
- alguns níveis de RAID (tais como RAID 1 e 5) só podem suportar uma única unidade com falha.
- As matrizes RAID, e os dados nelas contidos, estão num estado vulnerável até que uma unidade avariada seja substituída e o novo disco seja preenchido com dados.
- Porque as unidades têm agora uma capacidade muito maior do que quando o RAID foi implementado pela primeira vez, demora muito mais tempo a reconstruir unidades avariadas.
- Se ocorrer uma falha de disco, existe a possibilidade de os discos restantes conterem sectores defeituosos ou dados ilegíveis – o que pode tornar impossível a reconstrução completa da matriz.
No entanto, os níveis de RAID aninhados resolvem estes problemas proporcionando um maior grau de redundância, diminuindo significativamente as probabilidades de uma falha de array-level devido a falhas de disco simultâneas.
História do RAID
O termo RAID foi cunhado em 1987 por David Patterson, Randy Katz e Garth A. Gibson. No seu relatório técnico de 1988, “A Case for Redundant Arrays of Inexpensive Disks (RAID)”, os três argumentaram que um conjunto de unidades baratas poderia bater o desempenho das principais unidades de disco da época. Ao utilizar redundância, uma matriz RAID poderia ser mais fiável do que qualquer unidade de disco.
Embora este relatório tenha sido o primeiro a dar um nome ao conceito, a utilização de discos redundantes já estava a ser discutida por outros. Gus German da Geac Computer Corp. e Ted Grunau referiam-se pela primeira vez a esta ideia como MF-100. Norman Ken Ouchi da IBM apresentou uma patente em 1977 para a tecnologia, que mais tarde foi nomeada RAID 4. Em 1983, a Digital Equipment Corp. enviou as unidades que se tornariam RAID 1, e em 1986, foi registada outra patente da IBM para o que viria a tornar-se RAID 5. Patterson, Katz e Gibson também analisaram o que estava a ser feito por empresas como a Tandem Computers, Thinking Machines e Maxstor para definir as suas taxonomias RAID.
Embora os níveis de RAID listados no relatório de 1988 colocassem essencialmente nomes a tecnologias que já estavam em uso, a criação de terminologia comum para o conceito ajudou a estimular o mercado de armazenamento de dados a desenvolver mais produtos de matriz RAID.
Segundo Katz, o termo barato na sigla foi rapidamente substituído por independente pelos vendedores da indústria devido às implicações dos baixos custos.
O futuro do RAID
RAID não está completamente morto, mas muitos analistas dizem que a tecnologia se tornou obsoleta nos últimos anos. Alternativas como a codificação de apagamento oferecem uma melhor protecção de dados (embora a um preço mais elevado), e foram desenvolvidas com a intenção de resolver os pontos fracos do RAID. À medida que a capacidade da unidade aumenta, aumenta também a possibilidade de erro com uma matriz RAID, e as capacidades estão constantemente a aumentar.
O aumento das unidades de estado sólido (SSDs) é também visto como aliviando a necessidade de RAID. Os SSDs não têm partes móveis e não falham tão frequentemente como as unidades de disco rígido. As matrizes SSD utilizam frequentemente técnicas como o nivelamento por desgaste em vez de confiar no RAID para protecção de dados. A computação em hiper-escala também elimina a necessidade de RAID utilizando servidores redundantes em vez de unidades redundantes.
P>Pára, o RAID continua a ser uma parte arraigada do armazenamento de dados por agora e os principais fornecedores de tecnologia ainda lançam produtos RAID. A IBM lançou o RAID Distribuído IBM com o seu Spectrum Virtualize V7.6, que promete aumentar o desempenho RAID. A última versão da Intel Rapid Storage Technology suporta RAID 0, RAID 1, RAID 5 e RAID 10, e o software de gestão ONTAP da NetApp utiliza RAID para proteger contra até três falhas de drive simultâneas. A plataforma da Unidade EMC da Dell também suporta RAID 1/0, RAID 5 e RAID 6.
.