RAID (Redundant Array of Independent Disks)
RAID (Redundant Array of Independent Disks) ist eine Möglichkeit, die gleichen Daten an verschiedenen Stellen auf mehreren Festplatten oder Solid-State-Laufwerken zu speichern, um die Daten im Falle eines Laufwerksausfalls zu schützen. Es gibt jedoch verschiedene RAID-Levels, und nicht alle haben das Ziel, Redundanz zu bieten.
Wie RAID funktioniert
RAID funktioniert, indem es Daten auf mehreren Festplatten platziert und erlaubt, dass sich Ein-/Ausgabe-Operationen (E/A) auf ausgewogene Weise überschneiden, was die Leistung verbessert. Da die Verwendung mehrerer Festplatten die mittlere Zeit zwischen zwei Ausfällen (MTBF) erhöht, erhöht die redundante Speicherung von Daten auch die Fehlertoleranz.
RAID-Arrays erscheinen dem Betriebssystem (OS) als ein einziges logisches Laufwerk. RAID nutzt die Techniken des Disk Mirroring oder Disk Striping. Beim Mirroring werden identische Daten auf mehrere Laufwerke kopiert. Beim Striping werden die Daten über mehrere Laufwerke verteilt. Der Speicherplatz eines jeden Laufwerks wird in Einheiten von einem Sektor (512 Byte) bis zu mehreren Megabyte aufgeteilt. Die Stripes aller Festplatten werden ineinander verschachtelt und der Reihe nach adressiert.

Die Spiegelung von Platten und das Striping von Platten können auch in einem RAID-Verbund kombiniert werden.
In einem Einzelbenutzersystem, in dem große Datensätze gespeichert werden, werden die Stripes typischerweise so eingerichtet, dass sie klein sind (vielleicht 512 Byte), so dass sich ein einzelner Datensatz über alle Festplatten erstreckt und durch gleichzeitiges Lesen aller Festplatten schnell zugegriffen werden kann.
In einem Mehrbenutzersystem erfordert eine bessere Leistung einen Stripe, der breit genug ist, um den typischen oder maximal großen Datensatz aufzunehmen, was eine überlappende Platten-E/A über die Laufwerke hinweg ermöglicht.
RAID-Controller
Ein RAID-Controller ist ein Gerät, das zur Verwaltung von Festplatten in einem Speicher-Array verwendet wird. Er kann als Abstraktionsebene zwischen dem Betriebssystem und den physischen Festplatten verwendet werden und stellt Gruppen von Festplatten als logische Einheiten dar. Die Verwendung eines RAID-Controllers kann die Leistung verbessern und helfen, Daten im Falle eines Absturzes zu schützen.
Ein RAID-Controller kann hardware- oder softwarebasiert sein. Bei einem hardwarebasierten RAID-Produkt verwaltet ein physischer Controller das Array. Der Controller kann auch für die Unterstützung von Laufwerksformaten wie SATA und SCSI ausgelegt sein. Ein physischer RAID-Controller kann auch in die Hauptplatine eines Servers eingebaut sein.
Bei softwarebasiertem RAID nutzt der Controller die Ressourcen des Hardwaresystems, wie z. B. den zentralen Prozessor und den Speicher. Er führt zwar die gleichen Funktionen aus wie ein hardwarebasierter RAID-Controller, aber softwarebasierte RAID-Controller ermöglichen unter Umständen keinen so großen Leistungsschub und können die Leistung anderer Anwendungen auf dem Server beeinträchtigen.
Wenn eine Software-basierte RAID-Implementierung nicht mit dem Boot-Prozess eines Systems kompatibel ist und Hardware-basierte RAID-Controller zu kostspielig sind, ist Firmware- oder Treiber-basiertes RAID eine weitere mögliche Option.
Firmware-basierte RAID-Controller-Chips befinden sich auf dem Motherboard, und alle Operationen werden von der CPU ausgeführt, ähnlich wie bei Software-basiertem RAID. Bei Firmware wird das RAID-System jedoch nur zu Beginn des Bootvorgangs implementiert. Sobald das Betriebssystem geladen ist, übernimmt der Controllertreiber die RAID-Funktionalität. Ein Firmware-RAID-Controller ist nicht so teuer wie eine Hardware-Option, belastet aber die CPU des Computers stärker. Firmware-basiertes RAID wird auch hardware-unterstütztes Software-RAID, Hybrid-Modell-RAID und Fake-RAID genannt.
RAID-Levels
Raid-Geräte verwenden verschiedene Versionen, die Levels genannt werden. Das Originalpapier, das den Begriff prägte und das Konzept des RAID-Setups entwickelte, definierte sechs RAID-Levels – 0 bis 5. Dieses nummerierte System ermöglichte es den IT-Mitarbeitern, RAID-Versionen zu unterscheiden. Die Anzahl der Level hat sich seitdem erweitert und wurde in drei Kategorien unterteilt: Standard-, verschachtelte und nicht standardmäßige RAID-Level.
Standard-RAID-Level
RAID 0. Diese Konfiguration hat Striping, aber keine Redundanz der Daten. Es bietet die beste Leistung, aber keine Fehlertoleranz.
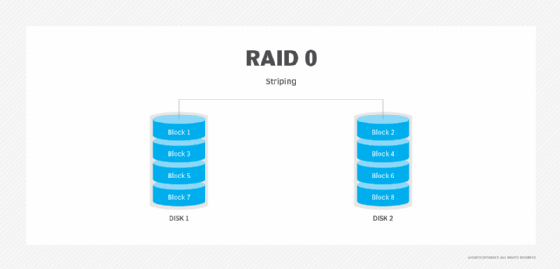
RAID 1. Auch als Plattenspiegelung bekannt, besteht diese Konfiguration aus mindestens zwei Laufwerken, die die Daten doppelt speichern. Es findet kein Striping statt. Die Leseleistung wird verbessert, da beide Festplatten gleichzeitig gelesen werden können. Die Schreibleistung ist die gleiche wie bei der Speicherung auf einer einzelnen Festplatte.
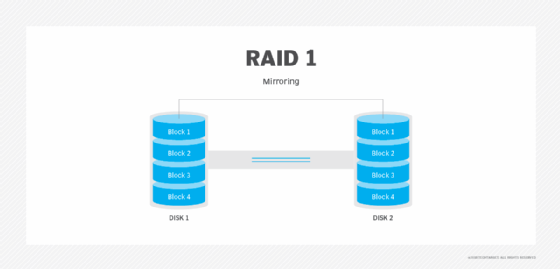
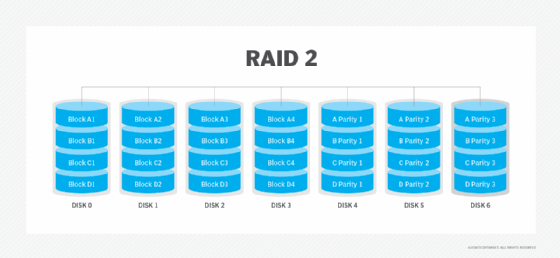
RAID 2. Diese Konfiguration verwendet Striping über Festplatten, wobei einige Festplatten Informationen zur Fehlerprüfung und -korrektur (ECC) speichern. RAID 2 verwendet außerdem eine spezielle Hamming-Code-Parität; eine lineare Form des Fehlerkorrekturcodes. RAID 2 hat keinen Vorteil gegenüber RAID 3 und wird nicht mehr verwendet.
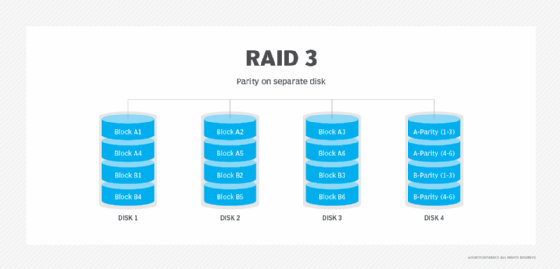
RAID 3. Diese Technik verwendet Striping und widmet ein Laufwerk zum Speichern von Paritätsinformationen. Die eingebetteten ECC-Informationen werden zur Fehlererkennung verwendet. Die Datenwiederherstellung erfolgt durch Berechnung der exklusiven Informationen, die auf den anderen Laufwerken gespeichert sind. Da ein E/A-Vorgang alle Laufwerke gleichzeitig anspricht, kann RAID 3 E/A nicht überlappen. Aus diesem Grund eignet sich RAID 3 am besten für Einzelplatzsysteme mit langen Aufzeichnungen.
RAID 4. Diese Ebene verwendet große Stripes, was bedeutet, dass ein Benutzer Datensätze von jedem einzelnen Laufwerk lesen kann. Überlappende E/A kann dann für Leseoperationen verwendet werden. Da alle Schreiboperationen erforderlich sind, um das Paritätslaufwerk zu aktualisieren, ist keine I/O-Überlappung möglich.
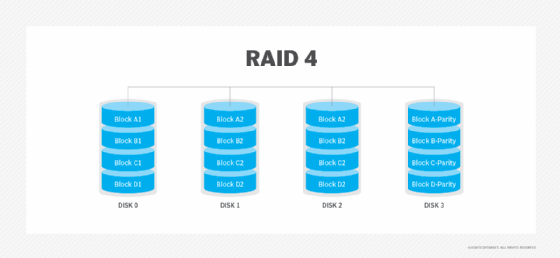
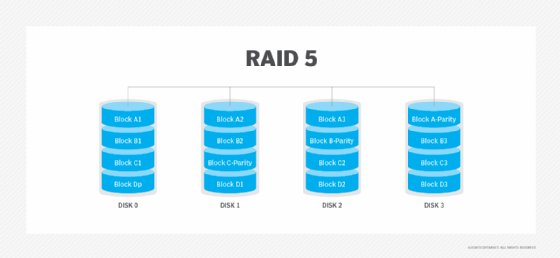
RAID 5. Diese Ebene basiert auf Paritäts-Block-Level-Striping. Die Paritätsinformationen werden über jedes Laufwerk gestriped, so dass das Array auch dann funktioniert, wenn ein Laufwerk ausfallen sollte. Die Architektur des Arrays ermöglicht es, Lese- und Schreibvorgänge auf mehrere Laufwerke zu verteilen – mit dem Ergebnis, dass die Leistung besser ist als bei einem einzelnen Laufwerk, aber nicht so hoch wie bei einem RAID 0-Array. RAID 5 erfordert mindestens drei Festplatten, aber es wird oft empfohlen, aus Leistungsgründen mindestens fünf Festplatten zu verwenden.
RAID 5-Arrays werden im Allgemeinen als schlechte Wahl für den Einsatz auf schreibintensiven Systemen angesehen, da die Leistung beim Schreiben von Paritätsdaten beeinträchtigt wird. Wenn eine Festplatte ausfällt, kann es sehr lange dauern, ein RAID 5-Array wiederherzustellen.
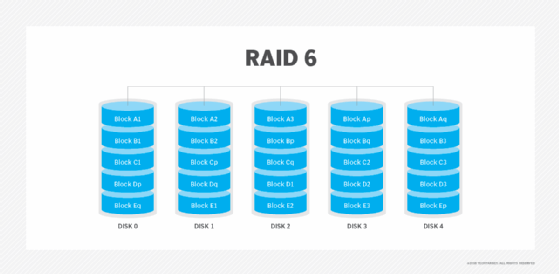
RAID 6. Diese Technik ist ähnlich wie RAID 5, aber sie beinhaltet ein zweites Paritätsschema, das über die Laufwerke im Array verteilt ist. Die Verwendung einer zusätzlichen Parität ermöglicht es dem Array, auch dann noch zu funktionieren, wenn zwei Festplatten gleichzeitig ausfallen. Dieser zusätzliche Schutz hat jedoch seinen Preis. RAID-6-Arrays haben oft eine langsamere Schreibleistung als RAID-5-Arrays.
Verschachtelte RAID-Level
Einige RAID-Level werden als verschachteltes RAID bezeichnet, da sie auf einer Kombination von RAID-Leveln basieren. Hier sind einige Beispiele für verschachtelte RAID-Levels.
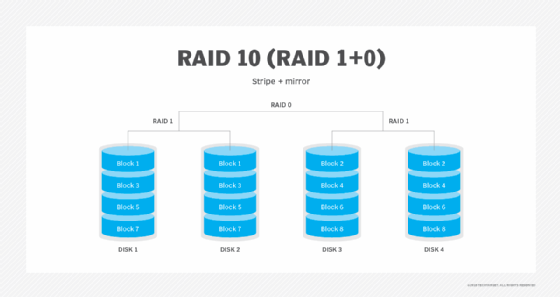
RAID 10 (RAID 1+0). Durch die Kombination von RAID 1 und RAID 0 wird dieser Level oft als RAID 10 bezeichnet, der eine höhere Leistung als RAID 1 bietet, allerdings zu deutlich höheren Kosten. Bei RAID 1+0 werden die Daten gespiegelt und die Spiegel sind gestreift.
RAID 01 (RAID 0+1). RAID 0+1 ist ähnlich wie RAID 1+0, nur die Methode der Datenorganisation ist etwas anders. Anstatt einen Spiegel zu erstellen und diesen dann zu spiegeln, erstellt RAID 0+1 einen Stripe-Satz und spiegelt dann den Stripe-Satz.
RAID 03 (RAID 0+3, auch bekannt als RAID 53 oder RAID 5+3). Dieser Level verwendet Striping (im Stil von RAID 0) für die virtuellen Festplattenblöcke von RAID 3. Dies bietet eine höhere Leistung als RAID 3, allerdings zu höheren Kosten.
RAID 50 (RAID 5+0). Diese Konfiguration kombiniert RAID 5 verteilte Parität mit RAID 0 Striping, um die Leistung von RAID 5 zu verbessern, ohne den Datenschutz zu verringern.
Nicht-Standard-RAID-Levels
Nicht-Standard-RAID-Levels unterscheiden sich von Standard-RAID-Levels und werden in der Regel von Firmen oder Organisationen für den hauptsächlich proprietären Gebrauch entwickelt. Hier sind einige Beispiele.
RAID 7. Ein nicht standardisierter RAID-Level, der auf RAID 3 und RAID 4 basiert und Caching hinzufügt. Es beinhaltet ein eingebettetes Echtzeit-Betriebssystem als Controller, Caching über einen Hochgeschwindigkeitsbus und andere Eigenschaften eines eigenständigen Computers.
Adaptive RAID. Bei diesem Level kann der RAID-Controller entscheiden, wie die Parität auf den Festplatten gespeichert werden soll. Er wählt zwischen RAID 3 und RAID 5, je nachdem, welcher RAID-Satztyp bei der Art der Daten, die auf die Festplatten geschrieben werden, besser funktioniert.
Linux MD RAID 10. Dieser vom Linux-Kernel bereitgestellte Level unterstützt die Erstellung von verschachtelten und nicht standardisierten RAID-Arrays. Linux-Software-RAID kann auch die Erstellung von Standard-RAID-0-, RAID-1-, RAID-4-, RAID-5- und RAID-6-Konfigurationen unterstützen.
Vorteile von RAID
Zu den Vorteilen von RAID gehören die folgenden.
- Eine Verbesserung der Kosteneffizienz, da preisgünstigere Festplatten in großer Anzahl verwendet werden.
- Durch die Verwendung mehrerer Festplatten kann RAID die Leistung einer einzelnen Festplatte verbessern.
- Erhöhte Geschwindigkeit des Computers und Zuverlässigkeit nach einem Absturz – je nach Konfiguration.
- Lese- und Schreibvorgänge können mit RAID 0 schneller durchgeführt werden als mit einer einzelnen Festplatte. Das liegt daran, dass ein Dateisystem aufgeteilt und auf Laufwerke verteilt wird, die gemeinsam an der gleichen Datei arbeiten.
- Eine erhöhte Verfügbarkeit und Ausfallsicherheit ist mit RAID 5 gegeben. Mit der Spiegelung können RAID-Arrays zwei Laufwerke haben, die dieselben Daten enthalten, wodurch sichergestellt wird, dass eines weiterhin funktioniert, wenn das andere ausfällt.
Nachteile der Verwendung von RAID
RAID hat jedoch auch seine Nachteile. Einige davon sind:
- Nested RAID-Levels sind teurer in der Implementierung als herkömmliche RAID-Levels, da sie eine größere Anzahl von Festplatten benötigen.
- Die Kosten pro Gigabyte an Speichergeräten sind bei Nested RAID höher, da viele der Laufwerke für die Redundanz verwendet werden.
- Wenn ein Laufwerk ausfällt, steigt die Wahrscheinlichkeit, dass ein anderes Laufwerk im Array ebenfalls bald ausfällt, was wahrscheinlich zu Datenverlust führen würde. Das liegt daran, dass alle Laufwerke in einem RAID-Verbund zur gleichen Zeit installiert werden, so dass alle Laufwerke dem gleichen Verschleiß unterliegen.
- Einige RAID-Levels (z. B. RAID 1 und 5) können nur einen einzigen Laufwerksausfall verkraften.
- RAID-Arrays und die darin enthaltenen Daten befinden sich in einem gefährdeten Zustand, bis ein ausgefallenes Laufwerk ausgetauscht und die neue Platte mit Daten bestückt wird.
- Da die Laufwerke heute eine viel größere Kapazität haben als zu Beginn der RAID-Implementierung, dauert es viel länger, ausgefallene Laufwerke wiederherzustellen.
- Wenn ein Festplattenfehler auftritt, besteht die Möglichkeit, dass die verbleibenden Festplatten fehlerhafte Sektoren oder unlesbare Daten enthalten – was es unmöglich machen kann, das Array vollständig wiederherzustellen.
Die verschachtelten RAID-Levels lösen diese Probleme, indem sie ein höheres Maß an Redundanz bieten und die Wahrscheinlichkeit eines Ausfalls auf Array-Ebene durch gleichzeitige Festplattenausfälle deutlich verringern.
Geschichte von RAID
Der Begriff RAID wurde 1987 von David Patterson, Randy Katz und Garth A. Gibson geprägt. In ihrem technischen Bericht „A Case for Redundant Arrays of Inexpensive Disks (RAID)“ aus dem Jahr 1988 argumentierten die drei, dass ein Array aus preiswerten Laufwerken die Leistung der damaligen Top-Laufwerke übertreffen kann. Durch die Verwendung von Redundanz könnte ein RAID-Array zuverlässiger sein als jedes einzelne Laufwerk.
Während dieser Bericht der erste war, der dem Konzept einen Namen gab, wurde die Verwendung von redundanten Festplatten bereits von anderen diskutiert. Gus German und Ted Grunau von der Geac Computer Corp. bezeichneten diese Idee zuerst als MF-100. IBMs Norman Ken Ouchi meldete 1977 ein Patent für die Technologie an, die später RAID 4 genannt wurde. Im Jahr 1983 lieferte Digital Equipment Corp. die Laufwerke aus, die später zu RAID 1 wurden, und 1986 wurde ein weiteres IBM-Patent für das spätere RAID 5 angemeldet. Patterson, Katz und Gibson sahen sich auch an, was Firmen wie Tandem Computers, Thinking Machines und Maxstor taten, um ihre RAID-Taxonomie zu definieren.
Während die im Bericht von 1988 aufgelisteten RAID-Stufen im Wesentlichen Technologien benannten, die bereits im Einsatz waren, trug die Schaffung einer gemeinsamen Terminologie für das Konzept dazu bei, den Datenspeichermarkt zur Entwicklung weiterer RAID-Array-Produkte anzuregen.
Laut Katz wurde der Begriff „inexpensive“ im Akronym von den Herstellern bald durch „independent“ ersetzt, da er niedrige Kosten implizierte.
Die Zukunft von RAID
RAID ist nicht ganz tot, aber viele Analysten sagen, dass die Technologie in den letzten Jahren veraltet ist. Alternativen wie Erasure Coding bieten einen besseren Datenschutz (wenn auch zu einem höheren Preis) und wurden mit der Absicht entwickelt, die Schwächen von RAID zu beheben. Mit zunehmender Laufwerkskapazität steigt auch die Fehlerwahrscheinlichkeit bei einem RAID-Array, und die Kapazitäten werden ständig erhöht.
Das Aufkommen von Solid-State-Laufwerken (SSDs) wird ebenfalls als Erleichterung für die Notwendigkeit von RAID angesehen. SSDs haben keine beweglichen Teile und fallen nicht so häufig aus wie Festplattenlaufwerke. SSD-Arrays verwenden oft Techniken wie Wear Leveling, anstatt sich auf RAID zum Schutz der Daten zu verlassen. Hyperscale Computing beseitigt auch die Notwendigkeit für RAID, indem redundante Server statt redundanter Laufwerke verwendet werden.
Doch RAID bleibt vorerst ein fester Bestandteil der Datenspeicherung und große Technologieanbieter bringen immer noch RAID-Produkte heraus. IBM hat IBM Distributed RAID mit seinem Spectrum Virtualize V7.6 herausgebracht, das verspricht, die RAID-Leistung zu steigern. Die neueste Version der Intel Rapid Storage Technology unterstützt RAID 0, RAID 1, RAID 5 und RAID 10, und die NetApp ONTAP Management-Software nutzt RAID zum Schutz vor bis zu drei gleichzeitigen Laufwerksausfällen. Die Dell EMC Unity-Plattform unterstützt auch RAID 1/0, RAID 5 und RAID 6.