Seleccionando el mejor algoritmo de Aprendizaje Automático para tu problema de regresión

Recientemente he comenzado un libro-centrado en la educación de los libros. Book Dives es un boletín quincenal en el que en cada nuevo número nos sumergimos en un libro de no ficción. Aprenderás las lecciones principales del libro y cómo aplicarlas en la vida real. Puedes suscribirte a él aquí.
Cuando se aborda cualquier tipo de problema de aprendizaje automático (ML) hay muchos algoritmos diferentes para elegir. En el aprendizaje automático, hay algo que se llama el teorema «No Free Lunch» que básicamente establece que ningún algoritmo de ML es el mejor para todos los problemas. El rendimiento de los distintos algoritmos de ML depende en gran medida del tamaño y la estructura de los datos. Por lo tanto, la elección correcta del algoritmo a menudo no está clara a menos que probemos nuestros algoritmos directamente a través de la vieja prueba y error.
Pero, hay algunos pros y contras de cada algoritmo de ML que podemos utilizar como guía. Aunque un algoritmo no siempre será mejor que otro, hay algunas propiedades de cada algoritmo que podemos utilizar como guía para seleccionar el correcto rápidamente y afinar los hiperparámetros. Vamos a echar un vistazo a unos cuantos algoritmos de ML destacados para problemas de regresión y a establecer unas pautas sobre cuándo utilizarlos en función de sus puntos fuertes y débiles. Este post debería servir como una gran ayuda en la selección del mejor algoritmo de ML para su problema de regresión!
Justo antes de entrar en materia, eche un vistazo a la AI Smart Newsletter para leer lo último y lo mejor sobre la IA, el aprendizaje automático y la ciencia de los datos!
Regresión lineal y polinómica
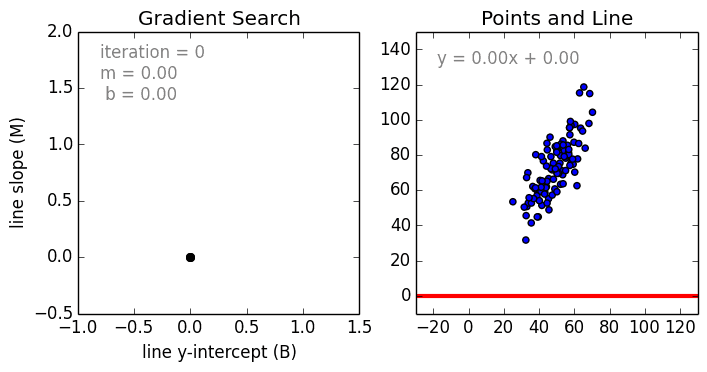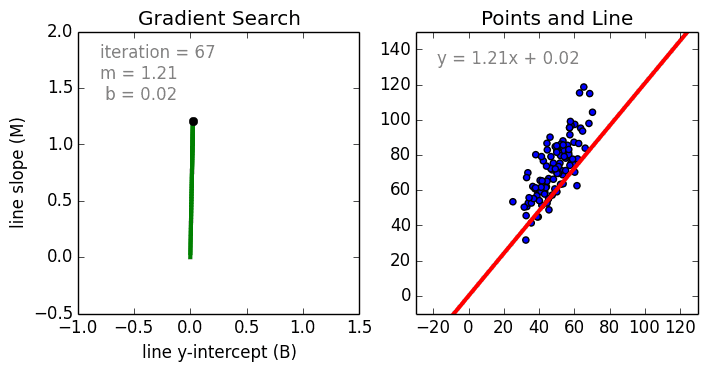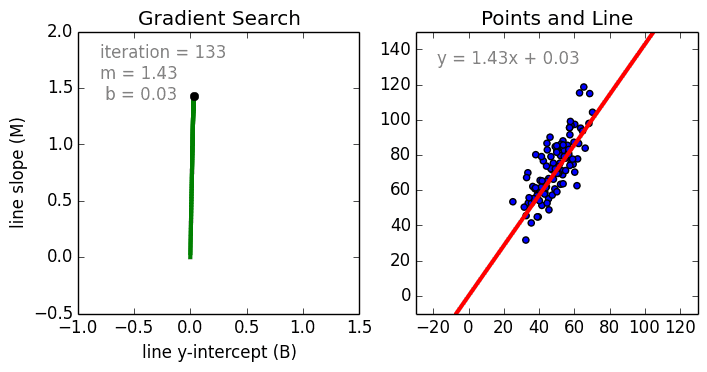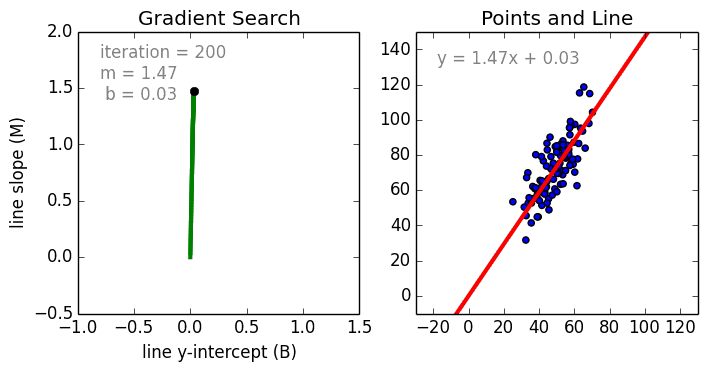
Comenzando por el caso simple, La regresión lineal de una sola variable es una técnica utilizada para modelar la relación entre una sola variable independiente de entrada (variable característica) y una variable dependiente de salida utilizando un modelo lineal, es decir, una línea.es decir, una línea. El caso más general es la regresión lineal multivariable, en la que se crea un modelo para la relación entre múltiples variables de entrada independientes (variables de características) y una variable dependiente de salida. El modelo sigue siendo lineal en el sentido de que la salida es una combinación lineal de las variables de entrada.
Hay un tercer caso más general llamado Regresión Polinómica en el que el modelo se convierte en una combinación no lineal de las variables de características, es decir, puede haber variables exponenciales, seno y coseno, etc. Sin embargo, esto requiere conocer la relación entre los datos y el resultado. Los modelos de regresión se pueden entrenar utilizando el Descenso Gradiente Estocástico (SGD).
Pros:
- Rápido de modelar y es particularmente útil cuando la relación a modelar no es extremadamente compleja y si no se tienen muchos datos.
- La regresión lineal es sencilla de entender, lo que puede ser muy valioso para la toma de decisiones empresariales.
- Para los datos no lineales, la regresión polinómica puede ser bastante difícil de diseñar, ya que se debe tener cierta información sobre la estructura de los datos y la relación entre las variables de características.
- Como resultado de lo anterior, estos modelos no son tan buenos como otros cuando se trata de datos muy complejos.
- Dado que las redes neuronales pueden tener muchas capas (y por tanto parámetros) con no linealidades, son muy eficaces para modelar relaciones no lineales muy complejas.
- En general, no tenemos que preocuparnos por la estructura de los datos en las redes neuronales son muy flexibles en el aprendizaje de casi cualquier tipo de relaciones de variables de características.
- La investigación ha demostrado consistentemente que simplemente dar a la red más datos de entrenamiento, ya sea totalmente nuevo o de aumentar el conjunto de datos original, beneficia el rendimiento de la red.
- Debido a la complejidad de estos modelos, no son fáciles de interpretar y entender.
- Pueden ser bastante desafiantes y computacionalmente intensivos de entrenar, requiriendo una cuidadosa sintonía de hiperparámetros y la configuración del programa de tasa de aprendizaje.
- Requieren muchos datos para lograr un alto rendimiento y generalmente son superados por otros algoritmos de ML en casos de «datos pequeños».
- Grandes en el aprendizaje de relaciones complejas, altamente no lineales. Por lo general, pueden lograr un rendimiento bastante alto, mejor que la regresión polinómica y a menudo a la par con las redes neuronales.
- Muy fácil de interpretar y entender. Aunque el modelo final entrenado puede aprender relaciones complejas, los límites de decisión que se construyen durante el entrenamiento son fáciles y prácticos de entender.
- Debido a la naturaleza del entrenamiento de los árboles de decisión pueden ser propensos a un sobreajuste importante. Un modelo de árbol de decisión completo puede ser demasiado complejo y contener una estructura innecesaria. Aunque esto a veces puede aliviarse utilizando una poda de árboles adecuada y conjuntos de bosques aleatorios más grandes.
- El uso de conjuntos de bosques aleatorios más grandes para lograr un mayor rendimiento tiene el inconveniente de ser más lento y requerir más memoria.
Contra:
Redes neuronales
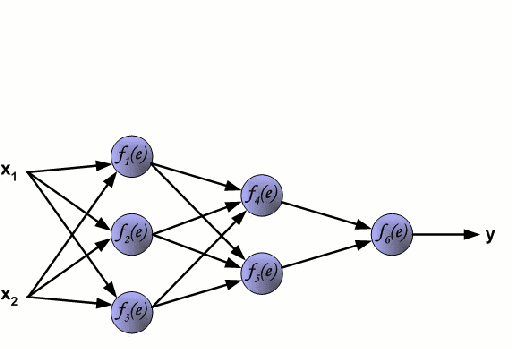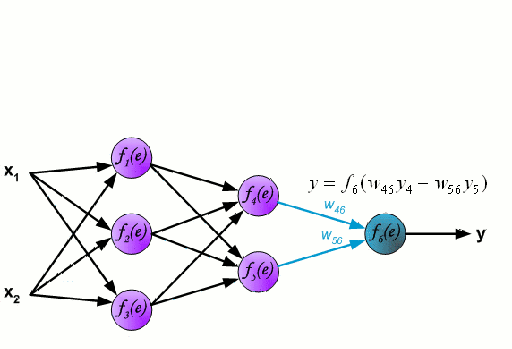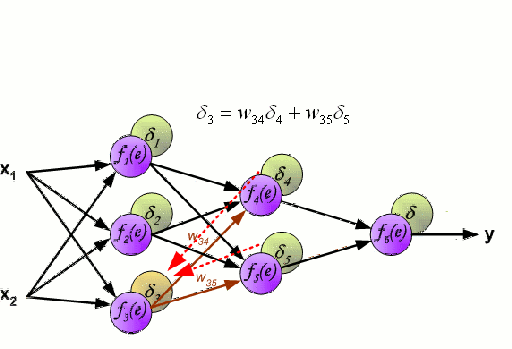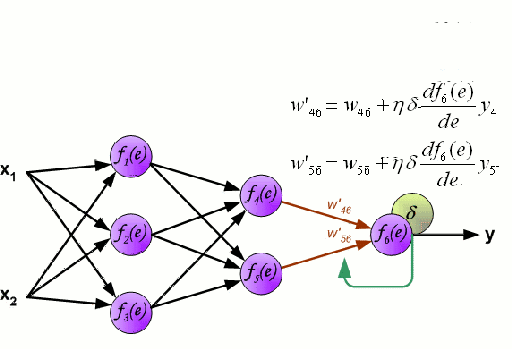
.
Una Red Neural consiste en un grupo interconectado de nodos llamados neuronas. Las variables de característica de entrada de los datos se pasan a estas neuronas como una combinación lineal multivariable, donde los valores multiplicados por cada variable de característica se conocen como pesos. A continuación, se aplica una no linealidad a esta combinación lineal que da a la red neuronal la capacidad de modelar relaciones no lineales complejas. Una red neuronal puede tener varias capas en las que la salida de una capa pasa a la siguiente de la misma manera. En la salida, generalmente no se aplica ninguna no linealidad. Las redes neuronales se entrenan utilizando el Descenso Gradiente Estocástico (SGD) y el algoritmo de retropropagación (ambos mostrados en el GIF de arriba).
Pros:
Contra:
Árboles de regresión y bosques aleatorios
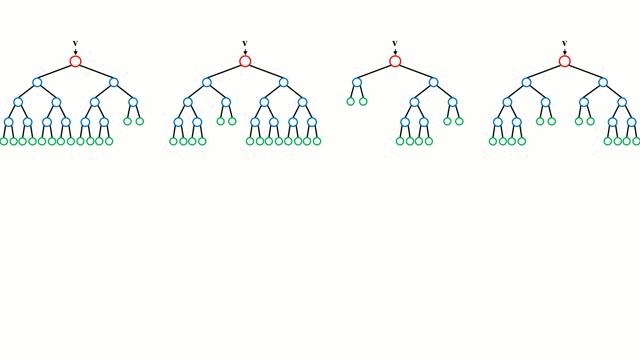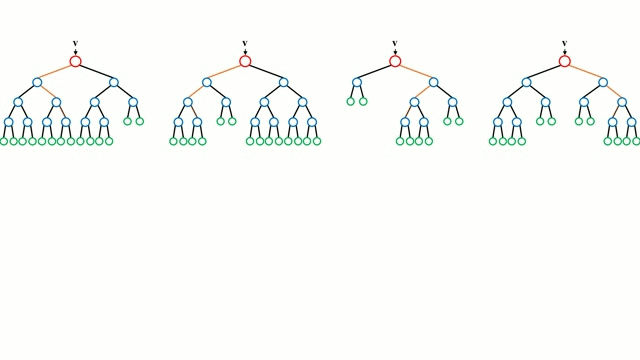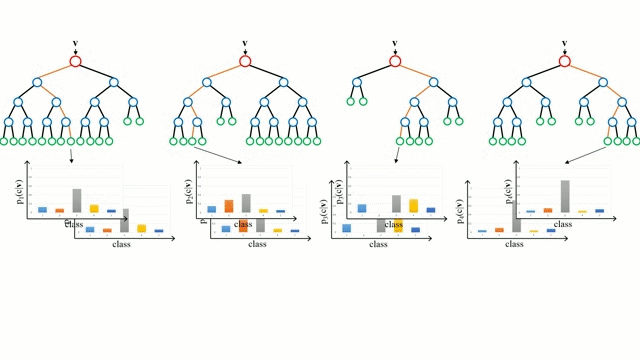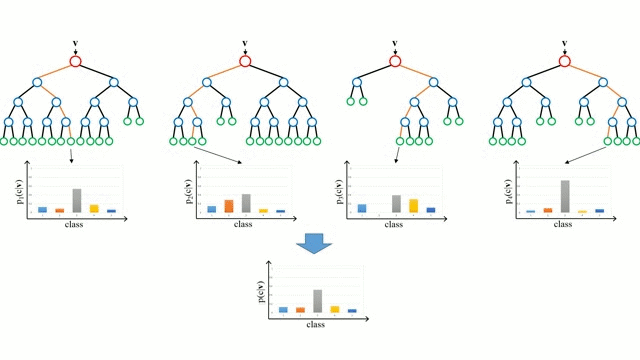
.
Comenzando por el caso base, un Árbol de Decisión es un modelo intuitivo en el que se recorren las ramas del árbol y se selecciona la siguiente rama por la que hay que bajar basándose en una decisión en un nodo. La inducción del árbol es la tarea de tomar un conjunto de instancias de entrenamiento como entrada, decidir qué atributos son los mejores para dividir, dividir el conjunto de datos y repetir en los conjuntos de datos divididos resultantes hasta que todas las instancias de entrenamiento estén categorizadas. Mientras se construye el árbol, el objetivo es dividir en los atributos que crean los nodos hijos más puros posibles, lo que mantendría al mínimo el número de divisiones que habría que hacer para clasificar todas las instancias de nuestro conjunto de datos. La pureza se mide por el concepto de ganancia de información, que se refiere a cuánto habría que saber sobre una instancia no vista anteriormente para poder clasificarla correctamente. En la práctica, esto se mide comparando la entropía, o la cantidad de información necesaria para clasificar una única instancia de una partición del conjunto de datos actual, con la cantidad de información para clasificar una única instancia si la partición del conjunto de datos actual se dividiera aún más en un atributo determinado.
Los bosques aleatorios son simplemente un conjunto de árboles de decisión. El vector de entrada se ejecuta a través de múltiples árboles de decisión. Para la regresión, se promedia el valor de salida de todos los árboles; para la clasificación se utiliza un esquema de votación para determinar la clase final.
Pros:
Contrarios:
Conclusión
¡Boom! ¡Ahí tienes los pros y los contras! En el próximo post veremos los pros y contras de los diferentes modelos de clasificación. Espero que hayas disfrutado de este post y hayas aprendido algo nuevo y útil. Si lo has hecho, no dudes en darle unos aplausos.