Fiabilité inter-évaluateurs
Probabilité conjointe d’accordEdit
La probabilité conjointe d’accord est la mesure la plus simple et la moins robuste. Elle est estimée comme le pourcentage du temps où les évaluateurs sont d’accord dans un système d’évaluation nominal ou catégorique. Elle ne tient pas compte du fait que l’accord peut être le fruit du hasard. On peut se demander s’il est nécessaire de » corriger » l’accord fortuit ; certains suggèrent que, dans tous les cas, un tel ajustement devrait être basé sur un modèle explicite de la façon dont le hasard et l’erreur affectent les décisions des évaluateurs.
Lorsque le nombre de catégories utilisées est faible (par exemple 2 ou 3), la probabilité que 2 évaluateurs s’accordent par pur hasard augmente considérablement. En effet, les deux évaluateurs doivent se limiter au nombre limité d’options disponibles, ce qui a un impact sur le taux d’accord global, et pas nécessairement sur leur propension à un accord » intrinsèque » (un accord est considéré comme » intrinsèque » s’il n’est pas dû au hasard).
Par conséquent, la probabilité conjointe d’accord restera élevée même en l’absence d’accord » intrinsèque » entre les évaluateurs. On s’attend à ce qu’un coefficient de fiabilité inter-évaluateurs utile (a) soit proche de 0, lorsqu’il n’y a pas d’accord » intrinsèque « , et (b) augmente à mesure que le taux d’accord » intrinsèque » s’améliore. La plupart des coefficients de concordance corrigés par le hasard atteignent le premier objectif. Cependant, le second objectif n’est pas atteint par de nombreuses mesures corrigées par le hasard connues.
Statistiques de kappaEdit
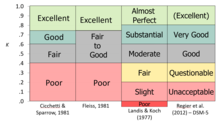
Le kappa est une façon de mesurer l’accord ou la fiabilité, en corrigeant la fréquence à laquelle les évaluations pourraient concorder par hasard. Le kappa de Cohen, qui fonctionne pour deux évaluateurs, et le kappa de Fleiss, une adaptation qui fonctionne pour n’importe quel nombre fixe d’évaluateurs, améliorent la probabilité conjointe en ce qu’ils prennent en compte la quantité d’accord qui pourrait se produire par hasard. Les versions originales souffraient du même problème que la probabilité conjointe en ce qu’elles traitent les données comme nominales et supposent que les notations n’ont pas d’ordre naturel ; si les données ont en fait un rang (niveau ordinal de mesure), alors cette information n’est pas pleinement prise en compte dans les mesures.
Les extensions ultérieures de l’approche comprenaient des versions qui pouvaient traiter le » crédit partiel » et les échelles ordinales. Ces extensions convergent avec la famille des corrélations intra-classes (ICC), il existe donc une manière conceptuellement liée d’estimer la fiabilité pour chaque niveau de mesure, du nominal (kappa) à l’ordinal (kappa ordinal ou ICC-élargissement des hypothèses) à l’intervalle (ICC, ou kappa ordinal-traitement de l’échelle d’intervalle comme ordinale), et au rapport (ICC). Il existe également des variantes qui permettent d’examiner l’accord des évaluateurs sur un ensemble d’éléments (par exemple, deux enquêteurs sont-ils d’accord sur les scores de dépression pour tous les éléments du même entretien semi-structuré pour un cas ?) ainsi que les évaluateurs x cas (par exemple, dans quelle mesure deux évaluateurs ou plus sont d’accord pour dire si 30 cas ont un diagnostic de dépression, oui/non – une variable nominale).
Le kappa est similaire à un coefficient de corrélation en ce sens qu’il ne peut pas dépasser +1,0 ou être inférieur à -1,0. Comme il est utilisé comme une mesure de l’accord, seules des valeurs positives seraient attendues dans la plupart des situations ; des valeurs négatives indiqueraient un désaccord systématique. Kappa ne peut atteindre des valeurs très élevées que lorsque la concordance est bonne et que le taux de la condition cible est proche de 50 % (car il inclut le taux de base dans le calcul des probabilités conjointes). Plusieurs autorités ont proposé des « règles empiriques » pour interpréter le niveau d’accord, dont beaucoup s’accordent sur l’essentiel même si les mots ne sont pas identiques.
Coefficients de corrélationModifier
Soit le r de Pearson {\displaystyle r}.

, le τ de Kendall ou le ρ de Spearman {\displaystyle \rho }.

peuvent être utilisés pour mesurer la corrélation par paire entre les évaluateurs utilisant une échelle ordonnée. La statistique de Pearson suppose que l’échelle d’évaluation est continue ; les statistiques de Kendall et de Spearman supposent seulement qu’elle est ordinale. Si plus de deux évaluateurs sont observés, un niveau moyen d’accord pour le groupe peut être calculé comme la moyenne des r {\displaystyle r}.
, τ, ou ρ {\displaystyle \rho }.
valeurs de chaque paire possible d’évaluateurs.
Coefficient de corrélation intra-classeModifier
Une autre façon de réaliser des tests de fiabilité est d’utiliser le coefficient de corrélation intra-classe (ICC). Il en existe plusieurs types et l’un d’eux est défini comme, « la proportion de la variance d’une observation due à la variabilité entre les sujets dans les vrais scores ». L’ICC peut être compris entre 0,0 et 1,0 (une première définition de l’ICC pouvait être comprise entre -1 et +1). L’ICC sera élevé lorsqu’il y a peu de variation entre les scores donnés à chaque item par les évaluateurs, par exemple si tous les évaluateurs donnent des scores identiques ou similaires à chacun des items. L’ICC est une amélioration par rapport au r de Pearson {\displaystyle r}.
et le ρ de Spearman {\displaystyle \rho }.
, car elle prend en compte les différences d’évaluation des segments individuels, ainsi que la corrélation entre les évaluateurs.
Les limites de l’accordModification

Une autre approche de l’accord (utile lorsqu’il y a des différences entre les segments). approche de la concordance (utile lorsqu’il n’y a que deux évaluateurs et que l’échelle est continue) consiste à calculer les différences entre chaque paire d’observations des deux évaluateurs. La moyenne de ces différences est appelée biais et l’intervalle de référence (moyenne ± 1,96 × écart-type) est appelé limites d’accord. Les limites d’accord donnent un aperçu de la quantité de variation aléatoire qui peut influencer les évaluations.
Si les évaluateurs ont tendance à s’accorder, les différences entre les observations des évaluateurs seront proches de zéro. Si un évaluateur est habituellement plus haut ou plus bas que l’autre d’une quantité constante, le biais sera différent de zéro. Si les évaluateurs ont tendance à ne pas être d’accord, mais sans que l’un d’entre eux ait tendance à donner une note plus élevée que l’autre, la moyenne sera proche de zéro. Les limites de confiance (généralement 95%) peuvent être calculées à la fois pour le biais et pour chacune des limites d’accord.
Il existe plusieurs formules qui peuvent être utilisées pour calculer les limites d’accord. La formule simple, qui a été donnée dans le paragraphe précédent et qui fonctionne bien pour une taille d’échantillon supérieure à 60, est
x ¯ ± 1,96 s {\displaystyle {\bar {x}}\pm 1,96s}.

Pour les échantillons de petite taille, une autre simplification courante est
x ¯ ± 2 s {\displaystyle {\bar {x}}\pm 2s}.

Cependant, la formule la plus précise (qui s’applique à toutes les tailles d’échantillon) est
x ¯ ± t 0,05 , n – 1 s 1 + 1 n {\displaystyle {\bar {x}}\pm t_{0,05,n-1}s{\sqrt {1+{\frac {1}{n}}}}}}.

Bland et Altman ont développé cette idée en représentant graphiquement la différence de chaque point, la différence moyenne et les limites d’accord sur la verticale par rapport à la moyenne des deux évaluations sur l’horizontale. Le graphique de Bland-Altman qui en résulte montre non seulement le degré global d’accord, mais aussi si l’accord est lié à la valeur sous-jacente de l’élément. Par exemple, deux évaluateurs pourraient s’entendre étroitement pour estimer la taille des petits éléments, mais ne pas être d’accord pour les éléments plus grands.
Lorsque l’on compare deux méthodes de mesure, il est non seulement intéressant d’estimer à la fois le biais et les limites de l’accord entre les deux méthodes (accord inter-évaluateurs), mais aussi d’évaluer ces caractéristiques pour chaque méthode en elle-même. Il se peut très bien que la concordance entre deux méthodes soit faible simplement parce que l’une des méthodes présente des limites de concordance larges alors que l’autre est étroite. Dans ce cas, la méthode dont les limites d’accord sont étroites serait supérieure d’un point de vue statistique, mais des considérations pratiques ou autres pourraient modifier cette appréciation. Ce qui constitue des limites d’accord étroites ou larges ou un biais important ou faible est une question d’évaluation pratique dans chaque cas.
L’alpha de KrippendorffEdit
L’alpha de Krippendorff est une statistique polyvalente qui évalue l’accord obtenu entre les observateurs qui catégorisent, évaluent ou mesurent un ensemble donné d’objets en fonction des valeurs d’une variable. Il généralise plusieurs coefficients d’accord spécialisés en acceptant un nombre quelconque d’observateurs, en étant applicable aux niveaux de mesure nominaux, ordinaux, d’intervalle et de rapport, en étant capable de traiter les données manquantes et en étant corrigé pour les petites tailles d’échantillon.
L’alpha est apparu dans l’analyse de contenu où les unités textuelles sont catégorisées par des codeurs formés et est utilisé dans le conseil et la recherche par sondage où les experts codent les données d’entretiens ouverts en termes analysables, dans la psychométrie où les attributs individuels sont testés par de multiples méthodes, dans les études d’observation où les événements non structurés sont enregistrés pour une analyse ultérieure, et dans la linguistique informatique où les textes sont annotés pour diverses qualités syntaxiques et sémantiques.
Les coefficients d’accord sont des coefficients d’accord spécialisés.