Inter-Rater-Reliabilität
Gemeinsame ÜbereinstimmungswahrscheinlichkeitBearbeiten
Die gemeinsame Übereinstimmungswahrscheinlichkeit ist das einfachste und am wenigsten robuste Maß. Sie wird als der Prozentsatz der Zeit geschätzt, in der die Rater in einem nominalen oder kategorialen Ratingsystem übereinstimmen. Sie berücksichtigt nicht die Tatsache, dass eine Übereinstimmung rein zufällig auftreten kann. Es ist umstritten, ob es notwendig ist, die zufällige Übereinstimmung zu „korrigieren“; einige schlagen vor, dass eine solche Anpassung auf jeden Fall auf einem expliziten Modell basieren sollte, wie Zufall und Fehler die Entscheidungen der Bewerter beeinflussen.
Wenn die Anzahl der verwendeten Kategorien klein ist (z.B. 2 oder 3), steigt die Wahrscheinlichkeit, dass zwei Bewerter durch reinen Zufall übereinstimmen, dramatisch an. Das liegt daran, dass sich beide Bewerter auf die begrenzte Anzahl der verfügbaren Optionen beschränken müssen, was sich auf die Gesamtübereinstimmungsrate auswirkt, und nicht unbedingt auf ihre Neigung zu „intrinsischer“ Übereinstimmung (eine Übereinstimmung wird als „intrinsisch“ betrachtet, wenn sie nicht auf Zufall zurückzuführen ist).
Daher bleibt die gemeinsame Wahrscheinlichkeit einer Übereinstimmung auch dann hoch, wenn es keine „intrinsische“ Übereinstimmung zwischen den Bewertern gibt. Es wird erwartet, dass ein nützlicher Inter-Rater-Reliabilitätskoeffizient (a) nahe bei 0 liegt, wenn es keine „intrinsische“ Übereinstimmung gibt, und (b) ansteigt, wenn sich die „intrinsische“ Übereinstimmungsrate verbessert. Die meisten zufallsbereinigten Übereinstimmungskoeffizienten erreichen das erste Ziel. Das zweite Ziel wird jedoch von vielen bekannten zufallsbereinigten Maßen nicht erreicht.
Kappa-StatistikBearbeiten
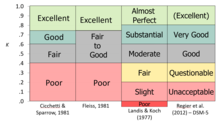
Kappa ist eine Methode zur Messung der Übereinstimmung oder Reliabilität, bei der korrigiert wird, wie oft Bewertungen zufällig übereinstimmen könnten. Cohens Kappa, das für zwei Bewerter funktioniert, und Fleiss‘ Kappa, eine Adaption, die für eine beliebige Anzahl von Bewertern funktioniert, verbessern die gemeinsame Wahrscheinlichkeit insofern, als sie die Menge an Übereinstimmung berücksichtigen, die durch Zufall zu erwarten wäre. Die ursprünglichen Versionen litten unter dem gleichen Problem wie die gemeinsame Wahrscheinlichkeit, da sie die Daten als nominal behandeln und davon ausgehen, dass die Bewertungen keine natürliche Ordnung haben; wenn die Daten tatsächlich einen Rang haben (ordinale Ebene der Messung), dann wird diese Information nicht vollständig in den Messungen berücksichtigt.
Spätere Erweiterungen des Ansatzes beinhalteten Versionen, die „partielle Kreditwürdigkeit“ und ordinale Skalen behandeln können. Diese Erweiterungen konvergieren mit der Familie der Intra-Klassen-Korrelationen (ICCs), so dass es eine konzeptionell verwandte Möglichkeit gibt, die Reliabilität für jedes Messniveau zu schätzen, von nominal (Kappa) über ordinal (ordinales Kappa oder ICC-streckende Annahmen) bis hin zu Intervall (ICC oder ordinales Kappa- Behandeln der Intervallskala als ordinal) und Verhältnis (ICCs). Es gibt auch Varianten, die die Übereinstimmung von Ratern über einen Satz von Items (z. B. stimmen zwei Interviewer über die Depressionswerte für alle Items desselben halbstrukturierten Interviews für einen Fall überein?) sowie von Ratern x Fällen (z. B. wie gut stimmen zwei oder mehr Rater darüber überein, ob 30 Fälle eine Depressionsdiagnose haben, ja/nein – eine nominale Variable) betrachten.
Kappa ist einem Korrelationskoeffizienten insofern ähnlich, als er nicht über +1,0 oder unter -1,0 liegen kann. Da er als Maß für die Übereinstimmung verwendet wird, würde man in den meisten Situationen nur positive Werte erwarten; negative Werte würden auf systematische Unstimmigkeiten hinweisen. Kappa kann nur dann sehr hohe Werte erreichen, wenn sowohl die Übereinstimmung gut ist als auch die Rate der Zielbedingung in der Nähe von 50% liegt (weil es die Basisrate in die Berechnung der gemeinsamen Wahrscheinlichkeiten einbezieht). Mehrere Autoritäten haben „Faustregeln“ für die Interpretation des Übereinstimmungsgrades angeboten, von denen viele im Kern übereinstimmen, obwohl die Wörter nicht identisch sind.
KorrelationskoeffizientenBearbeiten
Etweder Pearson’s r {\displaystyle r}

, Kendall’s τ oder Spearman’s ρ {\displaystyle \rho }

können zur Messung der paarweisen Korrelation zwischen Bewertern unter Verwendung einer geordneten Skala verwendet werden. Pearson geht davon aus, dass die Bewertungsskala kontinuierlich ist; Kendall- und Spearman-Statistiken gehen nur davon aus, dass sie ordinal ist. Wenn mehr als zwei Bewerter beobachtet werden, kann ein durchschnittlicher Grad der Übereinstimmung für die Gruppe als Mittelwert der r {\displaystyle r}
, τ, oder ρ {\displaystyle \rho }
Werte von jedem möglichen Paar von Bewertern.
Intra-Klassen-KorrelationskoeffizientBearbeiten
Eine weitere Möglichkeit, Reliabilitätstests durchzuführen, ist die Verwendung des Intra-Klassen-Korrelationskoeffizienten (ICC). Es gibt verschiedene Arten davon und einer ist definiert als „der Anteil der Varianz einer Beobachtung, der auf die Variabilität zwischen den Probanden in den wahren Werten zurückzuführen ist“. Der Bereich des ICC kann zwischen 0,0 und 1,0 liegen (eine frühere Definition des ICC lag zwischen -1 und +1). Der ICC wird hoch sein, wenn es wenig Variation zwischen den Bewertungen der einzelnen Items durch die Bewerter gibt, z. B. wenn alle Bewerter die gleichen oder ähnliche Bewertungen für jedes der Items abgeben. Der ICC ist eine Verbesserung gegenüber Pearson’s r.
und Spearman’s ρ {\displaystyle \rho }
, da es die Unterschiede in den Bewertungen für einzelne Segmente zusammen mit der Korrelation zwischen den Bewertern berücksichtigt.
Grenzen der ÜbereinstimmungBearbeiten

Eine weitere Ansatz für die Übereinstimmung (nützlich, wenn es nur zwei Bewerter gibt und die Skala kontinuierlich ist) ist die Berechnung der Differenzen zwischen jedem Paar der Beobachtungen der beiden Bewerter. Der Mittelwert dieser Differenzen wird als Bias bezeichnet und das Referenzintervall (Mittelwert ± 1,96 × Standardabweichung) wird als Grenzen der Übereinstimmung bezeichnet. Die Grenzen der Übereinstimmung geben Aufschluss darüber, wie viel zufällige Variation die Bewertungen beeinflussen kann.
Wenn die Bewerter tendenziell übereinstimmen, werden die Unterschiede zwischen den Beobachtungen der Bewerter nahe Null sein. Wenn ein Bewerter in der Regel um einen konstanten Betrag höher oder niedriger ist als der andere, ist die Verzerrung von Null verschieden. Wenn die Bewerter dazu neigen, nicht übereinzustimmen, aber ohne ein konsistentes Muster einer höheren Bewertung als die des anderen, wird der Mittelwert nahe Null sein. Konfidenzgrenzen (normalerweise 95%) können sowohl für den Bias als auch für jede der Übereinstimmungsgrenzen berechnet werden.
Es gibt mehrere Formeln, die zur Berechnung der Übereinstimmungsgrenzen verwendet werden können. Die einfache Formel, die im vorigen Abschnitt angegeben wurde und für einen Stichprobenumfang von mehr als 60 gut funktioniert, lautet
x ¯ ± 1,96 s {\displaystyle

Für kleinere Stichprobenumfänge ist eine weitere gängige Vereinfachung
x ¯ ± 2 s {\displaystyle {\bar {x}}\pm 2s}

Die genaueste Formel (die für alle Stichprobenumfänge gilt) ist jedoch
x ¯ ± t 0.05 , n – 1 s 1 + 1 n {\displaystyle {\bar {x}}\pm t_{0.05,n-1}s{\sqrt {1+{\frac {1}{n}}}}}

Bland und Altman haben diese Idee erweitert, indem sie die Differenz jedes Punktes, die mittlere Differenz und die Grenzen der Übereinstimmung auf der Vertikalen gegen den Durchschnitt der beiden Bewertungen auf der Horizontalen grafisch dargestellt haben. Das resultierende Bland-Altman-Diagramm zeigt nicht nur den Gesamtgrad der Übereinstimmung, sondern auch, ob die Übereinstimmung mit dem zugrunde liegenden Wert des Items zusammenhängt. So kann es sein, dass zwei Bewerter bei der Einschätzung der Größe von kleinen Items gut übereinstimmen, bei größeren Items aber nicht.
Beim Vergleich zweier Messmethoden ist es nicht nur von Interesse, sowohl die Verzerrung als auch die Grenzen der Übereinstimmung zwischen den beiden Methoden (Inter-Rater-Übereinstimmung) abzuschätzen, sondern diese Merkmale auch für jede Methode selbst zu bewerten. Es kann durchaus sein, dass die Übereinstimmung zwischen zwei Methoden nur deshalb schlecht ist, weil eine der Methoden weite Übereinstimmungsgrenzen hat, während die andere enge Grenzen hat. In diesem Fall wäre die Methode mit den engen Grenzen der Übereinstimmung aus statistischer Sicht überlegen, während praktische oder andere Überlegungen diese Einschätzung ändern könnten. Was enge oder weite Grenzen der Übereinstimmung oder eine große oder kleine Verzerrung ausmacht, ist in jedem Fall eine Frage der praktischen Beurteilung.
Krippendorffs alphaEdit
Krippendorffs Alpha ist eine vielseitige Statistik, die die Übereinstimmung zwischen Beobachtern bewertet, die eine gegebene Menge von Objekten in Bezug auf die Werte einer Variablen kategorisieren, bewerten oder messen. Es verallgemeinert mehrere spezialisierte Übereinstimmungskoeffizienten, indem es eine beliebige Anzahl von Beobachtern akzeptiert, auf Nominal-, Ordinal-, Intervall- und Ratio-Ebenen der Messung anwendbar ist, fehlende Daten behandeln kann und für kleine Stichprobengrößen korrigiert wird.
Alpha kam in der Inhaltsanalyse auf, wo Texteinheiten von geschulten Kodierern kategorisiert werden, und wird in der Beratungs- und Umfrageforschung verwendet, wo Experten offene Interviewdaten in analysierbare Begriffe kodieren, in der Psychometrie, wo einzelne Attribute mit mehreren Methoden getestet werden, in Beobachtungsstudien, wo unstrukturierte Ereignisse für die spätere Analyse aufgezeichnet werden, und in der Computerlinguistik, wo Texte für verschiedene syntaktische und semantische Qualitäten annotiert werden.