Inter-rater reliability
Probabilità congiunta di accordoModifica
La probabilità congiunta di accordo è la misura più semplice e meno robusta. È stimata come la percentuale di tempo in cui i valutatori sono d’accordo in un sistema di valutazione nominale o categorico. Non tiene conto del fatto che l’accordo può avvenire solo per caso. C’è qualche dubbio sulla necessità o meno di “correggere” l’accordo casuale; alcuni suggeriscono che, in ogni caso, qualsiasi aggiustamento dovrebbe essere basato su un modello esplicito di come il caso e l’errore influenzino le decisioni dei valutatori.
Quando il numero di categorie utilizzate è piccolo (ad esempio 2 o 3), la probabilità che due valutatori siano d’accordo per puro caso aumenta drammaticamente. Questo perché entrambi i valutatori devono limitarsi al numero limitato di opzioni disponibili, il che influisce sul tasso di accordo complessivo, e non necessariamente sulla loro propensione all’accordo “intrinseco” (un accordo è considerato “intrinseco” se non è dovuto al caso).
Quindi, la probabilità congiunta di accordo rimarrà alta anche in assenza di qualsiasi accordo “intrinseco” tra i valutatori. Ci si aspetta che un coefficiente di affidabilità inter-rater utile (a) sia vicino a 0, quando non c’è accordo “intrinseco”, e (b) aumenti quando il tasso di accordo “intrinseco” migliora. La maggior parte dei coefficienti di accordo corretti per caso raggiungono il primo obiettivo. Tuttavia, il secondo obiettivo non è raggiunto da molte misure corrette in base al caso.
Statistiche KappaModifica
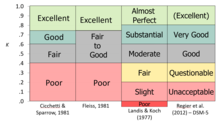
Kappa è un modo di misurare l’accordo o affidabilità, correggendo quanto spesso le valutazioni potrebbero concordare per caso. Il kappa di Cohen, che funziona per due valutatori, e il kappa di Fleiss, un adattamento che funziona per qualsiasi numero fisso di valutatori, migliorano la probabilità congiunta in quanto prendono in considerazione la quantità di accordo che potrebbe verificarsi per caso. Le versioni originali soffrivano dello stesso problema della probabilità congiunta in quanto trattano i dati come nominali e assumono che le valutazioni non abbiano un ordinamento naturale; se i dati hanno effettivamente un rango (livello ordinale di misurazione), allora questa informazione non è pienamente considerata nelle misurazioni.
Le estensioni successive dell’approccio includevano versioni che potevano gestire “credito parziale” e scale ordinali. Queste estensioni convergono con la famiglia delle correlazioni intra-classe (ICC), quindi c’è un modo concettualmente correlato di stimare l’affidabilità per ogni livello di misurazione, dal nominale (kappa) all’ordinale (kappa ordinale o ICC-stretching assumptions) all’intervallo (ICC, o kappa ordinale-trattando la scala intervallo come ordinale), e al rapporto (ICC). Ci sono anche varianti che possono esaminare l’accordo tra i valutatori su un insieme di item (ad esempio, due intervistatori sono d’accordo sui punteggi di depressione per tutti gli item della stessa intervista semi-strutturata per un caso?) così come i valutatori x i casi (ad esempio, quanto bene due o più valutatori sono d’accordo se 30 casi hanno una diagnosi di depressione, sì/no – una variabile nominale).
Kappa è simile a un coefficiente di correlazione in quanto non può andare sopra +1,0 o sotto -1,0. Poiché è usato come misura di accordo, ci si aspettano solo valori positivi nella maggior parte delle situazioni; valori negativi indicherebbero un disaccordo sistematico. Il Kappa può raggiungere valori molto alti solo quando l’accordo è buono e il tasso della condizione obiettivo è vicino al 50% (perché include il tasso base nel calcolo delle probabilità congiunte). Diverse autorità hanno offerto “regole empiriche” per interpretare il livello di accordo, molte delle quali concordano nella sostanza anche se le parole non sono identiche.
Coefficienti di correlazioneModifica
Oppure l’r di Pearson {\displaystyle r}

, τ di Kendall o ρ di Spearman {displaystyle \rho }

, τ, o ρ {displaystyle \rho }
valori di ogni possibile coppia di valutatori.
Coefficiente di correlazione intra-classeModifica
Un altro modo di eseguire test di affidabilità è quello di utilizzare il coefficiente di correlazione intra-classe (ICC). Ci sono diversi tipi di questo e uno è definito come “la proporzione della varianza di un’osservazione dovuta alla variabilità tra i soggetti nei punteggi veri”. L’intervallo dell’ICC può essere compreso tra 0,0 e 1,0 (una prima definizione di ICC potrebbe essere tra -1 e +1). L’ICC sarà alto quando c’è poca variazione tra i punteggi dati ad ogni item dai valutatori, per esempio se tutti i valutatori danno gli stessi o simili punteggi ad ogni item. L’ICC è un miglioramento dell’r di Pearson {displaystyle r}
e di Spearman ρ {displaystyle \rho }
, in quanto tiene conto delle differenze di valutazione per i singoli segmenti, insieme alla correlazione tra i valutatori.
Limiti dell’accordoModifica

Un altro approccio all’accordo (utile quando ci sono solo due classificatori e la scala è continua) è quello di calcolare le differenze tra ogni coppia di osservazioni dei due classificatori. La media di queste differenze è chiamata bias e l’intervallo di riferimento (media ± 1,96 × deviazione standard) è chiamato limite di accordo. I limiti di accordo forniscono un’idea di quanta variazione casuale può influenzare le valutazioni.
Se i valutatori tendono a concordare, le differenze tra le osservazioni dei valutatori saranno vicine allo zero. Se un valutatore è solitamente più alto o più basso dell’altro di una quantità consistente, la distorsione sarà diversa da zero. Se i valutatori tendono a non essere d’accordo, ma senza un modello coerente di una valutazione più alta dell’altra, la media sarà vicina allo zero. I limiti di confidenza (di solito il 95%) possono essere calcolati sia per il bias che per ciascuno dei limiti di accordo.
Ci sono diverse formule che possono essere usate per calcolare i limiti di accordo. La formula semplice, che è stata data nel paragrafo precedente e funziona bene per dimensioni del campione superiori a 60, è
x ¯ ± 1,96 s {\displaystyle {\bar {x}}pm 1,96s}

Per campioni più piccoli, un’altra semplificazione comune è
x ¯ ± 2 s {displaystyle {\bar {x}}\pm 2s}

Tuttavia, la formula più accurata (che è applicabile per tutte le dimensioni del campione) è
x ¯ ± t 0.05 , n – 1 s 1 + 1 n {\displaystyle {\bar {x}}}pm t_{0.05,n-1}s{\sqrt {1+{\frac {1}{n}}}}}

Bland e Altman hanno ampliato questa idea graficando la differenza di ogni punto, la differenza media, e i limiti di accordo sulla verticale contro la media delle due valutazioni sulla orizzontale. Il grafico Bland-Altman risultante dimostra non solo il grado complessivo di accordo, ma anche se l’accordo è legato al valore sottostante dell’item. Per esempio, due valutatori potrebbero essere molto d’accordo nello stimare la dimensione di oggetti piccoli, ma in disaccordo su oggetti più grandi.
Quando si confrontano due metodi di misurazione, non è solo interessante stimare sia la distorsione che i limiti di accordo tra i due metodi (accordo inter-rater), ma anche valutare queste caratteristiche per ogni metodo al proprio interno. Potrebbe benissimo essere che l’accordo tra due metodi sia scarso semplicemente perché uno dei metodi ha ampi limiti di accordo mentre l’altro li ha stretti. In questo caso, il metodo con i limiti di accordo stretti sarebbe superiore da un punto di vista statistico, mentre considerazioni pratiche o di altro tipo potrebbero cambiare questa valutazione. Ciò che costituisce limiti di accordo stretti o ampi o bias grandi o piccoli è una questione di valutazione pratica in ogni caso.
Modifica dell’alfa di Krippendorff
Krippendorff’s alpha è una statistica versatile che valuta l’accordo raggiunto tra gli osservatori che categorizzano, valutano o misurano un dato insieme di oggetti in termini di valori di una variabile. Generalizza diversi coefficienti di accordo specializzati accettando qualsiasi numero di osservatori, essendo applicabile a livelli di misura nominali, ordinali, intervalli e rapporti, essendo in grado di gestire i dati mancanti ed essendo corretto per piccole dimensioni del campione.
Alpha è emerso nell’analisi del contenuto in cui le unità testuali sono categorizzate da codificatori addestrati ed è usato nella consulenza e nella ricerca di sondaggi dove gli esperti codificano i dati delle interviste aperte in termini analizzabili, nella psicometria dove gli attributi individuali sono testati con metodi multipli, negli studi osservazionali dove gli eventi non strutturati sono registrati per la successiva analisi e nella linguistica computazionale dove i testi sono annotati per varie qualità sintattiche e semantiche.