評価者間信頼性
Joint probability of agreement編集
Joint-probability of agreementは、最もシンプルで最も堅牢性の低い指標です。 これは、名目またはカテゴリーの評価システムにおいて、評価者が一致した時間の割合として推定されます。 これは、偶然の一致という事実を考慮していません。 偶然の一致を「補正」する必要があるかどうかについては疑問がありますが、いずれにしても、そのような調整は、偶然とエラーが評価者の決定にどのように影響するかの明示的なモデルに基づいて行われるべきであるという意見もあります。
使用されるカテゴリの数が少ない場合 (例: 2 または 3)、2 人の評価者が純粋に偶然に一致する可能性は劇的に増加します。 これは、両方の評価者が限られた数の選択肢に限定しなければならないため、全体の一致率に影響を与え、必ずしも「本質的な」一致の傾向ではないからです (一致が偶然によるものではない場合、「本質的な」一致と見なされます)。 有用な評価者間信頼性係数は、(a) 「本質的な」一致がないときには 0 に近く、(b) 「本質的な」一致率が向上するにつれて増加することが期待されます。 ほとんどの偶然補正された一致係数は,最初の目的を達成しています。
Kappa statisticsEdit
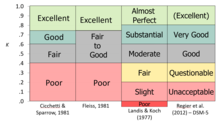
カッパは一致度や信頼性を測定する方法で、偶然に評価が一致することが多いことを補正します。 コーエンのカッパは2人の評価者に適用され、フリースのカッパは任意の数の評価者に適用されますが、共同確率を改良して、偶然に起こりうる一致の量を考慮に入れています。
オリジナルのバージョンは、データを名義で扱い、評価に自然な順序がないと仮定している点で、結合確率と同じ問題を抱えていました。もしデータに実際にランク (測定の順序レベル) がある場合、その情報は測定において完全には考慮されません。 これらの拡張は、クラス内相関 (ICC) のファミリーに収束するため、名目 (kappa) から順序 (順序 kappa または ICC-stretching assumptions) 、区間 (ICC、または区間尺度を順序として扱う順序 kappa) 、そして比率 (ICC) まで、各測定レベルの信頼性を推定する概念的に関連した方法があります。 また、評価者×症例(例えば、30症例がうつ病の診断を受けているかどうかについて、2人以上の評価者がどの程度同意しているか、YES/NO(名義変数))だけでなく、評価者の一致を項目のセット全体で見ることができるバリエーションもあります。
カッパは、+1.0を超えたり、-1.0を下回ったりすることができないという点で、相関係数に似ています。 これは一致の尺度として使用されるため、ほとんどの状況では正の値のみが期待され、負の値は系統的な不一致を示します。 Kappaが非常に高い値を示すのは、一致度が高く、対象となる条件の割合が50%に近い場合に限られる(結合確率の計算に基本的な割合が含まれているため)。
Correlation coefficientsEdit
Pearson’s r {\-displaystyle r}のいずれかである。

, Kendall’s τ, または Spearman’s ρ {displaystyle ˶ˆ꒳ˆ˵}のいずれかである。

は、順序付けされた尺度を使用する評価者間のペアワイズ相関を測定するために使用できます。 Pearsonは評価尺度が連続的であることを前提としており、KendallとSpearman統計は順序的であることのみを前提としています。 2人以上の評価者が観察された場合、グループの平均的な一致度は、r {displaystyle r}の平均として計算することができます。
, τ, or ρ {\\ rho }の平均値として計算できる。
の値を評価者の可能な各ペアから得る。
クラス内相関係数の編集
信頼性テストのもう一つの方法として、クラス内相関係数(ICC)があります。 これにはいくつかの種類があり、「真のスコアの被験者間の変動による観測値の変動の割合」と定義されています。 ICCの範囲は0.0~1.0です(初期のICCの定義では-1~+1でした)。 ICCは、すべての評価者が各項目に同じまたは類似のスコアを与えている場合など、評価者が各項目に与えたスコアの間にほとんど変動がない場合に高くなる。 ICCはPearson’s r{\\}よりも改善されている。
and Spearman’s ρ {displaystyle ˶ˆ꒳ˆ˵}.
評価者間の相関だけでなく、個々のセグメントの評価の違いも考慮しています。
合意の限界

もう一つの合意へのアプローチ(複数の評価者がいる場合に有効)。 一致へのもう一つのアプローチ(評価者が2人だけで、尺度が連続的な場合に有用)は、2人の評価者の観測値の各ペア間の差を計算することです。 これらの差の平均はバイアスと呼ばれ、基準区間(平均±1.96×標準偏差)は一致の限界と呼ばれています。
評価者の意見が一致する傾向にある場合、評価者の観測値の差はゼロに近くなります。 一方の評価者が他方の評価者よりも常に一定の量だけ高いまたは低い場合、その偏りはゼロとは異なります。 評価者が意見を異にする傾向があるが、一方の評価が他方より高いという一貫したパターンがない場合、平均はゼロに近い値になる。
一致の限界を計算するために使用できるいくつかの公式があります。
一致限界の計算にはいくつかの式がありますが、サンプルサイズが60以上の場合に有効なのは、前の段落で示した単純な式です。

サンプルサイズが小さい場合、もう一つの一般的な簡略化は
x ¯ ± 2 s {displaystyle {bar {x}}pm 2s}です。

しかし、最も正確な(全てのサンプルサイズに適用できる)公式は、
x ¯ ± t 0.05 , n – 1 s 1 + 1 n {\\{x}pm t_{0.05,n-1}s{\sqrt {1+{\frac {1}{n}}}}}}}です。

BlandとAltmanはこの考えを発展させ、各点の差、平均差、一致の限界を縦に、2つの評価の平均を横にグラフ化しました。 結果として得られるBland-Altmanプロットは、全体的な一致の度合いだけでなく、その一致がアイテムの基本的な価値に関連しているかどうかも示しています。
2つの測定方法を比較する場合、2つの方法の間のバイアスと一致の限界 (評価者間一致) を推定するだけでなく、各方法自体についてもこれらの特性を評価することが重要です。 2つの方法間の一致率が低いのは,単に一方の方法の一致限界が広く,他方の方法の一致限界が狭いためである可能性が高い. この場合、統計的には一致範囲の狭い方法が優れていると考えられますが、実用面やその他の理由で評価が変わる可能性があります。
Krippendorff’s alphaEdit
クリッペンドルフのアルファとは、ある変数の値によって対象物を分類、評価、測定する観察者の間で達成される一致を評価する多目的統計です。 これは、任意の数の観測者を受け入れること、名目、順序、区間、比率の測定レベルに適用できること、欠損データを扱えること、小さなサンプルサイズに補正できることなど、いくつかの特殊な一致係数を一般化したものです。
αは、訓練されたコーダーによってテキストユニットが分類されるコンテンツ分析の中で生まれました。また、専門家が自由形式のインタビューデータを分析可能な用語にコード化するカウンセリングや調査研究、個人の属性が複数の方法でテストされる心理測定学、構造化されていない出来事が後の分析のために記録される観察研究、テキストがさまざまな構文や意味の質について注釈される計算言語学でも使用されています
。