Interbeoordelaarsbetrouwbaarheid
Gezamenlijke waarschijnlijkheid van overeenstemmingEdit
De gezamenlijke waarschijnlijkheid van overeenstemming is de eenvoudigste en minst robuuste maat. Deze wordt geschat als het percentage van de tijd dat de beoordelaars het eens zijn in een nominaal of categorisch beoordelingssysteem. Hij houdt geen rekening met het feit dat overeenstemming louter op toeval kan berusten. Men kan zich afvragen of het nodig is te “corrigeren” voor toevallige overeenstemming; sommigen suggereren dat een dergelijke correctie in elk geval gebaseerd moet zijn op een expliciet model van hoe toeval en fouten de beslissingen van beoordelaars beïnvloeden.
Wanneer het aantal gebruikte categorieën klein is (b.v. 2 of 3), neemt de kans dat 2 beoordelaars het door puur toeval eens worden dramatisch toe. Dit komt omdat beide beoordelaars zich moeten beperken tot het beperkte aantal beschikbare opties, wat van invloed is op de totale mate van overeenstemming, en niet noodzakelijkerwijs op hun neiging tot “intrinsieke” overeenstemming (een overeenstemming wordt als “intrinsiek” beschouwd als zij niet aan het toeval te wijten is).
Daarom zal de gezamenlijke waarschijnlijkheid van overeenstemming hoog blijven, zelfs bij afwezigheid van enige “intrinsieke” overeenstemming tussen beoordelaars. Van een bruikbare interbeoordelaarsbetrouwbaarheidscoëfficiënt wordt verwacht (a) dat hij dicht bij 0 ligt, wanneer er geen “intrinsieke” overeenstemming is, en (b) dat hij toeneemt naarmate het “intrinsieke” overeenstemmingspercentage verbetert. De meeste voor toeval gecorrigeerde overeenstemmingscoëfficiënten bereiken de eerste doelstelling. De tweede doelstelling wordt echter door veel bekende toevalsgecorrigeerde maten niet bereikt.
Kappa-statistiekEdit
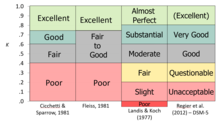
Kappa is een manier om overeenstemming of betrouwbaarheid te meten, waarbij wordt gecorrigeerd voor hoe vaak beoordelingen door toeval overeen zouden kunnen komen. Cohen’s kappa, die werkt voor twee beoordelaars, en Fleiss’ kappa, een aanpassing die werkt voor een vast aantal beoordelaars, verbeteren de gezamenlijke waarschijnlijkheid in die zin dat ze rekening houden met de hoeveelheid overeenkomst waarvan verwacht kan worden dat die door toeval ontstaat. De oorspronkelijke versies leden aan hetzelfde probleem als de gezamenlijke waarschijnlijkheid, omdat zij de gegevens als nominaal behandelden en aannamen dat de beoordelingen geen natuurlijke rangorde hebben; als de gegevens in werkelijkheid een rangorde hebben (ordinaal meetniveau), dan wordt die informatie niet volledig in de metingen verdisconteerd.
Latere uitbreidingen van de benadering omvatten versies die met “gedeeltelijke credit” en ordinale schalen overweg konden. Deze uitbreidingen convergeren naar de familie van intra-klasse correlaties (ICC’s), zodat er een conceptueel verwante manier is om de betrouwbaarheid te schatten voor elk meetniveau, van nominaal (kappa) naar ordinaal (ordinale kappa of ICC-stretching assumptions) naar interval (ICC, of ordinale kappa-treating the interval scale as ordinal), en ratio (ICC’s). Er zijn ook varianten die kunnen kijken naar overeenstemming tussen beoordelaars over een set items (bijv. zijn twee interviewers het eens over de depressiescores voor alle items van hetzelfde semi-gestructureerde interview voor één casus?) en tussen beoordelaars en casussen (bijv. hoe goed zijn twee of meer beoordelaars het eens over de vraag of 30 casussen een depressiediagnose hebben, ja/nee – een nominale variabele).
Kappa is vergelijkbaar met een correlatiecoëfficiënt in die zin dat hij niet hoger kan worden dan +1,0 of lager dan -1,0. Omdat het wordt gebruikt als een maat voor overeenstemming, zijn in de meeste situaties alleen positieve waarden te verwachten; negatieve waarden zouden duiden op systematische onenigheid. Kappa kan alleen zeer hoge waarden bereiken wanneer zowel de overeenstemming goed is als het percentage van de doelconditie in de buurt van 50% ligt (omdat het het basistarief meeneemt in de berekening van de gezamenlijke waarschijnlijkheden). Verscheidene autoriteiten hebben “vuistregels” geboden voor de interpretatie van de mate van overeenstemming, waarvan er vele het eens zijn in de kern, ook al zijn de woorden niet identiek.
CorrelatiecoëfficiëntenEdit
Ofwel Pearson’s r {{displaystyle r}

, Kendall’s τ, of Spearman’s ρ {{\displaystyle \rho }

kan worden gebruikt om de paarsgewijze correlatie te meten tussen beoordelaars die een geordende schaal gebruiken. Pearson gaat ervan uit dat de beoordelingsschaal continu is; Kendall en Spearman gaan er alleen van uit dat de schaal ordinaal is. Als meer dan twee beoordelaars worden geobserveerd, kan een gemiddeld niveau van overeenstemming voor de groep worden berekend als het gemiddelde van de r {\displaystyle r}
, τ, of ρ {\displaystyle \rho }
waarden van elk mogelijk paar beoordelaars.
Intra-klasse correlatiecoëfficiëntEdit
Een andere manier om betrouwbaarheidstests uit te voeren is het gebruik van de intra-klasse correlatiecoëfficiënt (ICC). Er zijn verschillende soorten, waarvan er een wordt gedefinieerd als: “het aandeel van de variantie van een waarneming dat toe te schrijven is aan de variabiliteit tussen de proefpersonen in de werkelijke scores”. Het bereik van de ICC kan liggen tussen 0,0 en 1,0 (een vroege definitie van ICC zou kunnen liggen tussen -1 en +1). De ICC zal hoog zijn als er weinig variatie is tussen de scores die de beoordelaars aan elk item geven, bv. als alle beoordelaars dezelfde of vergelijkbare scores geven aan elk van de items. De ICC is een verbetering ten opzichte van Pearson’s r {\displaystyle r}
en Spearman’s ρ {\displaystyle \rho }
, omdat deze rekening houdt met de verschillen in beoordelingen voor afzonderlijke segmenten, samen met de correlatie tussen beoordelaars.
Grenzen van overeenkomstEdit

Een andere benadering van overeenstemming (nuttig wanneer er slechts twee beoordelaars zijn en de schaal continu is) is het berekenen van de verschillen tussen de waarnemingen van elk paar van de twee beoordelaars. Het gemiddelde van deze verschillen wordt bias genoemd en het referentie-interval (gemiddelde ± 1,96 × standaarddeviatie) wordt akkoordgrenzen genoemd. De overeenstemminggrenzen geven inzicht in de mate waarin willekeurige variatie de beoordelingen kan beïnvloeden.
Als de beoordelaars de neiging hebben het met elkaar eens te zijn, zullen de verschillen tussen de waarnemingen van de beoordelaars vrijwel nul zijn. Als de ene beoordelaar gewoonlijk een consistent hoger of lager cijfer geeft dan de andere, zal de vertekening niet nul zijn. Als de beoordelaars de neiging hebben het oneens te zijn, maar zonder een consistent patroon waarbij de ene beoordelaar hoger beoordeelt dan de andere, zal het gemiddelde dicht bij nul liggen. Voor zowel de vertekening als voor elk van de overeenstemmingsgrenzen kunnen betrouwbaarheidsgrenzen (gewoonlijk 95%) worden berekend.
Er zijn verschillende formules die kunnen worden gebruikt om overeenstemmingsgrenzen te berekenen. De eenvoudige formule, die in de vorige paragraaf is gegeven en goed werkt voor steekproefgroottes groter dan 60, is
x ¯ ± 1,96 s {Displaystyle {bar {x}}pm 1,96s}
 Voor kleinere steekproeven is een andere gebruikelijke vereenvoudiging x ¯ ± 2 s {\displaystyle {\bar {x}}pm 2s}
Voor kleinere steekproeven is een andere gebruikelijke vereenvoudiging x ¯ ± 2 s {\displaystyle {\bar {x}}pm 2s}

De nauwkeurigste formule (die voor alle steekproefgroottes geldt) is echter
x ¯ ± t 0,05 , n – 1 s 1 + 1 n {\displaystyle {\bar {x}}¯ t_{0,05,n-1}s{\sqrt {1+{\frac {1}{n}}}}}

Bland en Altman hebben dit idee verder uitgewerkt door het verschil van elk punt, het gemiddelde verschil, en de grenzen van overeenstemming op de verticaal af te zetten tegen het gemiddelde van de twee beoordelingen op de horizontaal. De resulterende Bland-Altman plot toont niet alleen de algemene graad van overeenstemming aan, maar ook of de overeenstemming verband houdt met de onderliggende waarde van het item.
Bij het vergelijken van twee meetmethoden is het niet alleen van belang om de bias en de grenzen van de overeenstemming tussen de twee methoden (interbeoordelaarsovereenstemming) te schatten, maar ook om deze kenmerken voor elke methode afzonderlijk te beoordelen. Het is heel goed mogelijk dat de overeenstemming tussen twee methoden slecht is, gewoon omdat de ene methode ruime overeenstemminggrenzen heeft en de andere nauwe. In dat geval zou de methode met de nauwe overeenstemmingsgrenzen vanuit statistisch oogpunt superieur zijn, terwijl praktische of andere overwegingen deze beoordeling zouden kunnen wijzigen. Wat smalle of brede overeenstemmingsgrenzen zijn, of een grote of kleine bias, is een kwestie van een praktische beoordeling voor elk geval.
De alfa van Krippendorff
Krippendorffs alfa is een veelzijdige statistiek die de overeenstemming beoordeelt die wordt bereikt tussen waarnemers die een bepaalde verzameling objecten categoriseren, evalueren of meten in termen van de waarden van een variabele. De alfa veralgemeent verscheidene gespecialiseerde overeenstemmingscoëfficiënten door een willekeurig aantal waarnemers toe te laten, toepasbaar te zijn op nominale, ordinale, interval- en verhoudingsniveaus, in staat te zijn ontbrekende gegevens te verwerken, en te corrigeren voor kleine steekproefgroottes.
Alpha ontstond in inhoudsanalyse waar tekstuele eenheden worden gecategoriseerd door getrainde codeurs en wordt gebruikt in counseling en enquête-onderzoek waar deskundigen open interviewgegevens coderen in analyseerbare termen, in psychometrie waar individuele eigenschappen worden getest met meerdere methoden, in observationele studies waar ongestructureerde gebeurtenissen worden vastgelegd voor latere analyse, en in computationele linguïstiek waar teksten worden geannoteerd voor verschillende syntactische en semantische kwaliteiten.