Wiarygodność międzylaboratoryjna
Wspólne prawdopodobieństwo porozumieniaEdit
Wspólne prawdopodobieństwo porozumienia jest najprostszą i najmniej solidną miarą. Jest ona szacowana jako procent czasu, w którym oceniający zgadzają się w nominalnym lub kategorycznym systemie oceniania. Nie bierze pod uwagę faktu, że porozumienie może się zdarzyć wyłącznie na podstawie przypadku. Istnieje pewna wątpliwość, czy istnieje potrzeba „poprawiania” dla przypadkowego porozumienia; niektórzy sugerują, że w każdym przypadku, każda taka korekta powinna być oparta na wyraźnym modelu tego, jak przypadek i błąd wpływają na decyzje oceniających.
Gdy liczba używanych kategorii jest mała (np. 2 lub 3), prawdopodobieństwo, że dwóch oceniających zgodzi się przez czysty przypadek drastycznie wzrasta. Dzieje się tak, ponieważ obaj oceniający muszą ograniczyć się do ograniczonej liczby dostępnych opcji, co wpływa na ogólny wskaźnik zgodności, a niekoniecznie na ich skłonność do „wewnętrznego” porozumienia (porozumienie jest uważane za „wewnętrzne”, jeśli nie wynika z przypadku).
W związku z tym, wspólne prawdopodobieństwo porozumienia pozostanie wysokie nawet w przypadku braku „wewnętrznego” porozumienia między oceniającymi. Oczekuje się, że użyteczny współczynnik wiarygodności międzylaboratoryjnej (a) będzie bliski 0, gdy nie ma „wewnętrznej” zgodności, oraz (b) będzie wzrastał wraz z poprawą wskaźnika „wewnętrznej” zgodności. Większość współczynników zgodności skorygowanych o prawdopodobieństwo osiąga pierwszy cel. Jednakże, drugi cel nie jest osiągany przez wiele znanych miar skorygowanych o prawdopodobieństwo.
Statystyki KappaEdit
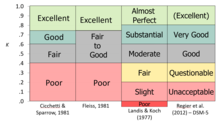
Kappa to sposób pomiaru zgodności lub rzetelności, korygujący o to, jak często oceny mogą zgadzać się przypadkowo. Kappy Cohena, która działa dla dwóch oceniających, oraz kappa Fleissa, adaptacja, która działa dla dowolnej stałej liczby oceniających, udoskonalają wspólne prawdopodobieństwo w ten sposób, że biorą pod uwagę ilość zgodności, której można się spodziewać w wyniku przypadku. Oryginalne wersje cierpiały na ten sam problem co wspólne prawdopodobieństwo, ponieważ traktowały dane jako nominalne i zakładały, że oceny nie mają naturalnego uporządkowania; jeśli dane rzeczywiście mają rangę (porządkowy poziom pomiaru), to ta informacja nie jest w pełni uwzględniana w pomiarach.
Późniejsze rozszerzenia tego podejścia obejmowały wersje, które mogły obsługiwać „częściowe uznanie” i skale porządkowe. Rozszerzenia te zbiegają się z rodziną korelacji wewnątrzklasowych (ICC), więc istnieje koncepcyjnie powiązany sposób szacowania rzetelności dla każdego poziomu pomiaru od nominalnego (kappa) do porządkowego (porządkowa kappa lub ICC – założenia rozciągające) do przedziałowego (ICC lub porządkowa kappa – traktowanie skali przedziałowej jako porządkowej) i stosunkowego (ICC). Istnieją również warianty, które pozwalają na sprawdzenie zgodności pomiędzy oceniającymi w odniesieniu do zestawu pozycji (np. czy dwóch oceniających zgadza się co do wyników depresji dla wszystkich pozycji w tym samym wywiadzie częściowo ustrukturalizowanym dla jednego przypadku?), jak również oceniających x przypadki (np. jak dobrze dwóch lub więcej oceniających zgadza się co do tego, czy 30 przypadków ma diagnozę depresji, tak/nie – zmienna nominalna).
Kappa jest podobna do współczynnika korelacji w tym sensie, że nie może przekroczyć +1,0 lub poniżej -1,0. Ponieważ jest on używany jako miara zgodności, w większości sytuacji należałoby się spodziewać jedynie wartości dodatnich; wartości ujemne wskazywałyby na systematyczny brak zgody. Kappa może osiągać bardzo wysokie wartości tylko wtedy, gdy zarówno zgodność jest dobra, jak i wskaźnik stanu docelowego jest bliski 50% (ponieważ uwzględnia wskaźnik podstawowy w obliczaniu wspólnego prawdopodobieństwa). Kilka autorytetów zaoferowało „reguły kciuka” dla interpretacji poziomu porozumienia, z których wiele zgadza się w sednie, nawet jeśli słowa nie są identyczne.
Współczynniki korelacjiEdit
Współczynnik korelacji r Pearsona {\i0}

, τ Kendalla, lub ρ Spearmana {{displaystyle ρ }

mogą być używane do pomiaru korelacji parami wśród oceniających przy użyciu skali, która jest uporządkowana. Pearson zakłada, że skala ocen jest ciągła; statystyki Kendalla i Spearmana zakładają jedynie, że jest ona porządkowa. Jeśli obserwuje się więcej niż dwóch oceniających, średni poziom zgodności dla grupy może być obliczony jako średnia z r {{displaystyle r}}
, τ, lub ρ {displaystyle \rho }
z każdej możliwej pary oceniających.
Współczynnik korelacji wewnątrzklasowejEdit
Innym sposobem przeprowadzenia badania wiarygodności jest wykorzystanie współczynnika korelacji wewnątrzklasowej (ICC). Istnieje kilka rodzajów tego współczynnika, a jeden z nich jest zdefiniowany jako „część wariancji obserwacji spowodowana zmiennością międzyprzedmiotową w prawdziwych wynikach”. Zakres ICC może wynosić od 0,0 do 1,0 (wczesna definicja ICC mogła wynosić od -1 do +1). ICC będzie wysokie, kiedy istnieje małe zróżnicowanie pomiędzy punktami przyznanymi każdemu z elementów przez osoby oceniające, np. jeśli wszyscy oceniający przyznają takie same lub podobne punkty dla każdego z elementów. ICC jest udoskonaleniem współczynnika r Pearsona {{displaystyle r}}.
i ρ Spearmana {{displaystyle \rho }
, ponieważ uwzględnia różnice w ocenach poszczególnych segmentów oraz korelację między oceniającymi.
Granice zgodnościEdit

Inne podejście do zagadnienia zgodności (przydatne, gdy występują różnice w ocenach). Inne podejście do porozumienia (przydatne, gdy jest tylko dwóch oceniających i skala jest ciągła) polega na obliczeniu różnic między każdą parą obserwacji dwóch oceniających. Średnia z tych różnic jest określana jako błąd systematyczny, a przedział odniesienia (średnia ± 1,96 × odchylenie standardowe) jest określany jako granice porozumienia. The limits of agreement provide insight into how much random variation may be influencing the ratings.
Jeśli osoby oceniające mają tendencję do zgadzania się, różnice między obserwacjami osób oceniających będą bliskie zeru. Jeśli jeden z oceniających jest zazwyczaj wyższy lub niższy od drugiego o stałą wartość, skośność będzie różna od zera. Jeśli oceniający mają tendencję do nie zgadzania się, ale bez stałego wzorca jednej oceny wyższej od drugiej, średnia będzie bliska zeru. Granice ufności (zazwyczaj 95%) mogą być obliczone zarówno dla błędu systematycznego jak i dla każdej z granic porozumienia.
Istnieje kilka wzorów, które mogą być użyte do obliczenia granic porozumienia. Prosty wzór, który został podany w poprzednim akapicie i działa dobrze dla wielkości próbki większej niż 60, jest następujący
x ¯ ± 1,96 s {{displaystyle {{bar {x}}} } }

Dla mniejszych wielkości próbek, innym często stosowanym uproszczeniem jest
x ¯ ± 2 s {displaystyle {{bar{x}}} \pm 2s}

Jednakże najdokładniejszym wzorem (który ma zastosowanie dla wszystkich wielkości próbek) jest
x ¯ ± t 0.05 , n – 1 s 1 + 1 n {displaystyle {{bar {x}} t_{0.05,n-1}s {{sqrt {1+{frac {1}{n}}}}}

Bland i Altman rozwinęli ten pomysł, sporządzając wykres różnicy każdego punktu, średniej różnicy i granic porozumienia w pionie względem średniej z dwóch ocen w poziomie. Wynikowy wykres Blanda-Altmana pokazuje nie tylko ogólny stopień zgodności, ale również to, czy zgodność jest związana z podstawową wartością elementu. Na przykład, dwaj oceniający mogą być zgodni w szacowaniu wielkości małych przedmiotów, ale nie zgadzają się co do większych przedmiotów.
Przy porównywaniu dwóch metod pomiaru, interesujące jest nie tylko oszacowanie zarówno błędu systematycznego jak i granic zgodności pomiędzy dwoma metodami (umowa pomiędzy recenzentami), ale również ocena tych cech dla każdej metody w obrębie siebie. Może się bardzo dobrze zdarzyć, że zgodność między dwiema metodami jest słaba po prostu dlatego, że jedna z metod ma szerokie granice zgodności, podczas gdy druga ma wąskie. W tym przypadku metoda o wąskich granicach zgodności bylaby lepsza ze statystycznego punktu widzenia, podczas gdy względy praktyczne lub inne moglyby zmienić tę ocenę. Co stanowi wąską lub szeroką granicę zgodności lub dużą lub małą stronniczość jest kwestią praktycznej oceny w każdym przypadku.
Alfa KrippendorffaEdit
Alfa Krippendorffa to uniwersalna statystyka oceniająca porozumienie osiągnięte wśród obserwatorów, którzy kategoryzują, oceniają lub mierzą dany zbiór obiektów pod względem wartości zmiennej. Uogólnia ona kilka wyspecjalizowanych współczynników zgodności poprzez akceptację dowolnej liczby obserwatorów, możliwość zastosowania do nominalnych, porządkowych, interwałowych i stosunkowych poziomów pomiaru, zdolność do obsługi brakujących danych oraz korektę dla małych rozmiarów próby.
Alfa pojawiła się w analizie treści, gdzie jednostki tekstowe są kategoryzowane przez przeszkolonych koderów i jest używana w doradztwie i badaniach ankietowych, gdzie eksperci kodują dane z wywiadów otwartych na możliwe do przeanalizowania terminy, w psychometrii, gdzie indywidualne atrybuty są testowane wieloma metodami, w badaniach obserwacyjnych, gdzie nieustrukturyzowane wydarzenia są rejestrowane w celu późniejszej analizy, oraz w lingwistyce komputerowej, gdzie teksty są anotowane pod kątem różnych jakości składniowych i semantycznych.