Fiabilidade entre os médicos
Probabilidade conjunta de acordoEditar
A probabilidade conjunta de acordo é a medida mais simples e a menos robusta. É estimada como a percentagem do tempo que os avaliadores concordam num sistema de classificação nominal ou categórica. Não tem em conta o facto de que o acordo pode acontecer apenas com base no acaso. Há alguma questão se há ou não necessidade de “corrigir” o acordo por acaso; alguns sugerem que, em qualquer caso, qualquer ajustamento deste tipo deve basear-se num modelo explícito de como o acaso e o erro afectam as decisões dos avaliadores.
Quando o número de categorias utilizadas é pequeno (por exemplo 2 ou 3), a probabilidade de 2 avaliadores concordarem por puro acaso aumenta dramaticamente. Isto porque ambos os avaliadores devem limitar-se ao número limitado de opções disponíveis, o que tem impacto na taxa de acordo global, e não necessariamente na sua propensão para acordo “intrínseco” (um acordo é considerado “intrínseco” se não for devido ao acaso).
Por conseguinte, a probabilidade conjunta de acordo permanecerá elevada mesmo na ausência de qualquer acordo “intrínseco” entre os avaliadores. Espera-se que um coeficiente de fiabilidade útil entre avaliadores (a) seja próximo de 0, quando não há acordo “intrínseco”, e (b) aumente à medida que a taxa de acordo “intrínseco” melhora. A maioria dos coeficientes de acordo corrigidos por acaso alcançam o primeiro objectivo. Contudo, o segundo objectivo não é alcançado por muitas medidas conhecidas de correcção de probabilidade.
Estatísticas KappaEditar
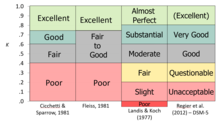
Kappa é uma forma de medir a concordância ou fiabilidade, corrigindo a frequência com que as classificações podem concordar por acaso. A kappa de Cohen, que funciona para dois avaliadores, e a kappa de Fleiss, uma adaptação que funciona para qualquer número fixo de avaliadores, melhoram a probabilidade conjunta na medida em que têm em conta a quantidade de acordo que se poderia esperar que ocorresse através do acaso. As versões originais sofreram do mesmo problema que a probabilidade conjunta, na medida em que tratam os dados como nominais e assumem que as classificações não têm uma ordenação natural; se os dados têm efectivamente uma classificação (nível ordinal de medição), então essa informação não é totalmente considerada nas medições.
Extensões posteriores da abordagem incluíram versões que poderiam lidar com “crédito parcial” e escalas ordinais. Estas extensões convergem com a família de correlações intra-classe (ICCs), pelo que existe uma forma conceptualmente relacionada de estimar a fiabilidade para cada nível de medição desde o nominal (kappa) ao ordinal (kappa ordinal ou pressupostos de alongamento ICC) até ao intervalo (ICC, ou kappa ordinal – tratando a escala de intervalo como ordinal), e rácio (ICCs). Existem também variantes que podem ser consideradas de acordo pelos avaliadores através de um conjunto de itens (por exemplo, dois avaliadores concordam sobre a pontuação da depressão para todos os itens na mesma entrevista semi-estruturada para um caso?), bem como avaliadores x casos (por exemplo, até que ponto dois ou mais avaliadores concordam sobre se 30 casos têm um diagnóstico de depressão, sim/não – uma variável nominal).
Kappa é semelhante a um coeficiente de correlação na medida em que não pode ir acima de +1,0 ou abaixo de -1,0. Uma vez que é utilizado como medida de concordância, só seriam esperados valores positivos na maioria das situações; valores negativos indicariam um desacordo sistemático. Kappa só pode atingir valores muito elevados quando ambos os acordos são bons e a taxa da condição alvo está perto dos 50% (porque inclui a taxa base no cálculo das probabilidades conjuntas). Várias autoridades propuseram “regras de conduta” para a interpretação do nível de concordância, muitas das quais concordam no essencial, embora as palavras não sejam idênticas.
Coeficientes de correlaçãoEditar
Code Pearson’s r {\displaystyle r}

, Kendall’s τ, ou Spearman’s ρ {\i1}displaystyle {\i1}rho

pode ser usado para medir a correlação de pares entre os avaliadores usando uma escala que é ordenada. Pearson assume que a escala de classificação é contínua; as estatísticas de Kendall e Spearman assumem apenas que é ordinal. Se forem observados mais de dois avaliadores, um nível médio de concordância para o grupo pode ser calculado como a média do r {\displaystyle r}.
, τ, ou ρ {\i1}displaystyle {\i}
valores de cada possível par de avaliadores.
Coeficiente de correlação intra-classeEditar
Outra forma de realizar testes de fiabilidade é utilizar o coeficiente de correlação intra-classe (ICC). Existem vários tipos deste e um é definido como, “a proporção de variância de uma observação devido à variabilidade entre sujeitos nas pontuações verdadeiras”. O intervalo do ICC pode estar entre 0,0 e 1,0 (uma definição precoce do ICC pode estar entre -1 e +1). O ICC será elevado quando houver pouca variação entre as pontuações dadas a cada item pelos avaliadores, por exemplo, se todos os avaliadores derem as mesmas pontuações ou pontuações semelhantes a cada um dos itens. O ICC é uma melhoria em relação ao r {\displaystyle r} de Pearson.
e Spearman’s ρ {\displaystyle {\displaystyle \rho}
, uma vez que tem em conta as diferenças nas classificações para segmentos individuais, juntamente com a correlação entre os avaliadores.
Limites do acordoEdit

Outro A abordagem de acordo (útil quando existem apenas dois avaliadores e a escala é contínua) é calcular as diferenças entre cada par de observações dos dois avaliadores. A média destas diferenças é designada por viés e o intervalo de referência (média ± 1,96 × desvio padrão) é designado por limites de concordância. Os limites de concordância dão uma ideia da variação aleatória que pode estar a influenciar as classificações.
Se os avaliadores tenderem a concordar, as diferenças entre as observações dos avaliadores serão próximas de zero. Se um avaliador for normalmente superior ou inferior ao outro por um montante consistente, o enviesamento será diferente de zero. Se os avaliadores tendem a discordar, mas sem um padrão consistente de uma classificação superior à outra, a média será perto de zero. Os limites de confiança (normalmente 95%) podem ser calculados tanto para o viés como para cada um dos limites de concordância.
Existem várias fórmulas que podem ser utilizadas para calcular os limites de concordância. A fórmula simples, que foi dada no parágrafo anterior e funciona bem para amostras de tamanho superior a 60, é
x ¯ ± 1,96 s {\i1}s

p> Para amostras de tamanho menor, outra simplificação comum é x ¯ ± 2 s ¯ estilo de exibição {\an8} 2s

No entanto, a fórmula mais precisa (aplicável a todos os tamanhos de amostras) é
x ¯ ± t 0,05 , n – 1 s 1 + 1 n {\i1}displaystyle {\i}pm t_{0,05,n-1}s{\i}sqrt {1+{\i}{n}}}}}

Bland e Altman expandiram esta ideia através do gráfico da diferença de cada ponto, a diferença média, e os limites de concordância na vertical em relação à média das duas classificações na horizontal. O gráfico Bland-Altman resultante demonstra não só o grau global de concordância, mas também se a concordância está relacionada com o valor subjacente do item. Por exemplo, dois avaliadores podem concordar estreitamente na estimativa do tamanho de itens pequenos, mas discordam sobre itens maiores.
Ao comparar dois métodos de medição, não só é interessante estimar tanto o enviesamento como os limites de concordância entre os dois métodos (concordância entre avaliadores), mas também avaliar estas características para cada método dentro de si. Pode muito bem ser que a concordância entre dois métodos seja pobre simplesmente porque um dos métodos tem amplos limites de concordância enquanto o outro tem limites estreitos. Neste caso, o método com os limites estreitos de concordância seria superior do ponto de vista estatístico, enquanto que considerações práticas ou outras poderiam alterar esta apreciação. O que constitui limites estreitos ou largos de concordância, ou preconceitos grandes ou pequenos, é uma questão de avaliação prática em cada caso.
h3> AlfaEdit de Krippendorff
Krippendorff’s alpha é uma estatística versátil que avalia o acordo alcançado entre observadores que categorizam, avaliam ou medem um determinado conjunto de objectos em termos dos valores de uma variável. Generaliza vários coeficientes de concordância especializada aceitando qualquer número de observadores, sendo aplicável a níveis de medição nominais, ordinais, de intervalo, e de rácio, sendo capaz de lidar com dados em falta, e sendo corrigido para pequenos tamanhos de amostras.
Alpha surgiu na análise de conteúdo onde as unidades textuais são categorizadas por codificadores treinados e é utilizada em aconselhamento e investigação de inquéritos onde os peritos codificam dados de entrevistas abertas em termos analisáveis, em psicometria onde os atributos individuais são testados por múltiplos métodos, em estudos observacionais onde são registados acontecimentos não estruturados para análise subsequente, e em linguística computacional onde os textos são anotados para várias qualidades sintácticas e semânticas.