Fiabilidad entre evaluadores
Probabilidad conjunta de acuerdoEditar
La probabilidad conjunta de acuerdo es la medida más sencilla y menos robusta. Se estima como el porcentaje de veces que los calificadores están de acuerdo en un sistema de calificación nominal o categórica. No tiene en cuenta el hecho de que el acuerdo puede producirse únicamente por azar. Se cuestiona si es necesario o no «corregir» el acuerdo por azar; algunos sugieren que, en cualquier caso, cualquier ajuste de este tipo debería basarse en un modelo explícito de cómo el azar y el error afectan a las decisiones de los calificadores.
Cuando el número de categorías que se utiliza es pequeño (por ejemplo, 2 o 3), la probabilidad de que dos calificadores coincidan por puro azar aumenta drásticamente. Esto se debe a que ambos calificadores deben limitarse al número limitado de opciones disponibles, lo que repercute en la tasa de acuerdo global, y no necesariamente en su propensión al acuerdo «intrínseco» (un acuerdo se considera «intrínseco» si no se debe al azar).
Por lo tanto, la probabilidad conjunta de acuerdo seguirá siendo alta incluso en ausencia de cualquier acuerdo «intrínseco» entre los calificadores. Se espera que un coeficiente útil de fiabilidad entre evaluadores (a) se acerque a 0, cuando no hay acuerdo «intrínseco», y (b) aumente a medida que mejore el índice de acuerdo «intrínseco». La mayoría de los coeficientes de concordancia corregidos por el azar alcanzan el primer objetivo. Sin embargo, el segundo objetivo no lo consiguen muchas medidas conocidas corregidas por el azar.
Estadística KappaEditar
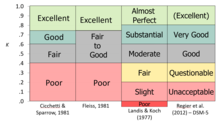
Kappa es una forma de medir la concordancia o fiabilidad, corrigiendo la frecuencia con la que las calificaciones pueden coincidir por azar. La kappa de Cohen, que funciona para dos calificadores, y la kappa de Fleiss, una adaptación que funciona para cualquier número fijo de calificadores, mejoran la probabilidad conjunta en el sentido de que tienen en cuenta la cantidad de acuerdo que podría esperarse que se produjera por azar. Las versiones originales sufrían el mismo problema que la probabilidad conjunta en el sentido de que tratan los datos como nominales y asumen que las calificaciones no tienen un orden natural; si los datos tienen realmente un rango (nivel ordinal de medición), entonces esa información no se considera completamente en las mediciones.
Las extensiones posteriores del enfoque incluían versiones que podían manejar «crédito parcial» y escalas ordinales. Estas extensiones convergen con la familia de correlaciones intraclase (CCI), por lo que existe una forma conceptualmente relacionada de estimar la fiabilidad para cada nivel de medición, desde el nominal (kappa) hasta el ordinal (kappa ordinal o CCI-estirando los supuestos), pasando por el intervalo (CCI, o kappa ordinal-tratando la escala de intervalo como ordinal), y la proporción (CCI). También hay variantes que pueden analizar el acuerdo de los calificadores en un conjunto de ítems (por ejemplo, ¿coinciden dos entrevistadores en las puntuaciones de depresión de todos los ítems de la misma entrevista semiestructurada para un caso?), así como calificadores x casos (por ejemplo, en qué medida coinciden dos o más calificadores sobre si 30 casos tienen un diagnóstico de depresión, sí/no-una variable nominal).
Kappa es similar a un coeficiente de correlación en el sentido de que no puede estar por encima de +1,0 ni por debajo de -1,0. Dado que se utiliza como medida de acuerdo, en la mayoría de las situaciones sólo se esperarían valores positivos; los valores negativos indicarían un desacuerdo sistemático. Kappa sólo puede alcanzar valores muy altos cuando el acuerdo es bueno y el índice de la condición objetivo se acerca al 50% (porque incluye el índice base en el cálculo de las probabilidades conjuntas). Varias autoridades han ofrecido «reglas empíricas» para interpretar el nivel de acuerdo, muchas de las cuales coinciden en lo esencial aunque las palabras no sean idénticas.
Coeficientes de correlaciónEditar
Tanto la r de Pearson {\displaystyle r}

, la τ de Kendall, o la ρ de Spearman {\displaystyle \rho }

pueden utilizarse para medir la correlación por pares entre calificadores que utilizan una escala que está ordenada. Pearson supone que la escala de valoración es continua; los estadísticos de Kendall y Spearman sólo suponen que es ordinal. Si se observan más de dos calificadores, puede calcularse un nivel medio de acuerdo para el grupo como la media de las r
, τ, o ρ {\displaystyle \rho }
valores de cada posible par de calificadores.
Coeficiente de correlación intraclaseEditar
Otra forma de realizar pruebas de fiabilidad es utilizar el coeficiente de correlación intraclase (CCI). Hay varios tipos y uno de ellos se define como «la proporción de la varianza de una observación debida a la variabilidad entre sujetos en las puntuaciones verdaderas». El rango del CCI puede estar entre 0,0 y 1,0 (una primera definición del CCI podría estar entre -1 y +1). El CCI será alto cuando haya poca variación entre las puntuaciones dadas a cada ítem por los calificadores, por ejemplo, si todos los calificadores dan las mismas o similares puntuaciones a cada uno de los ítems. El ICC es una mejora de la r de Pearson.
y el ρ de Spearman {\displaystyle \rho }
, ya que tiene en cuenta las diferencias en las calificaciones de los segmentos individuales, junto con la correlación entre calificadores.
Límites de la concordanciaEditar

Otro enfoque de la concordancia (útil cuando los calificadores enfoque de la concordancia (útil cuando sólo hay dos calificadores y la escala es continua) es calcular las diferencias entre cada par de observaciones de los dos calificadores. La media de estas diferencias se denomina sesgo y el intervalo de referencia (media ± 1,96 × desviación estándar) se denomina límites de acuerdo. Los límites de concordancia proporcionan una idea de la cantidad de variación aleatoria que puede estar influyendo en las calificaciones.
Si los calificadores tienden a estar de acuerdo, las diferencias entre las observaciones de los calificadores serán cercanas a cero. Si uno de los calificadores suele ser más alto o más bajo que el otro por una cantidad consistente, el sesgo será diferente de cero. Si los calificadores tienden a estar en desacuerdo, pero sin un patrón consistente de una calificación más alta que la otra, la media será cercana a cero. Se pueden calcular los límites de confianza (normalmente el 95%) tanto para el sesgo como para cada uno de los límites de acuerdo.
Hay varias fórmulas que se pueden utilizar para calcular los límites de acuerdo. La fórmula simple, que se dio en el párrafo anterior y que funciona bien para un tamaño de muestra superior a 60, es
x ¯ ± 1,96 s

Para tamaños de muestra más pequeños, otra simplificación común es
x ¯ ± 2 s {\displaystyle {\bar {x}}\pm 2s}

Sin embargo, la fórmula más precisa (que es aplicable para todos los tamaños de muestra) es
x ¯ ± t 0,05 , n – 1 s 1 + 1 n {\displaystyle {\bar {x}\pm t_{0,05,n-1}s{{}sqrt {1+{\frac {1}{n}}}}}

Bland y Altman han ampliado esta idea graficando la diferencia de cada punto, la diferencia media y los límites de acuerdo en la vertical contra la media de las dos valoraciones en la horizontal. El gráfico de Bland-Altman resultante demuestra no sólo el grado de acuerdo general, sino también si el acuerdo está relacionado con el valor subyacente del ítem. Por ejemplo, dos calificadores pueden coincidir estrechamente en la estimación del tamaño de los ítems pequeños, pero estar en desacuerdo sobre los ítems más grandes.
Cuando se comparan dos métodos de medición, no sólo es interesante estimar tanto el sesgo como los límites del acuerdo entre los dos métodos (acuerdo entre calificadores), sino también evaluar estas características para cada método dentro de sí mismo. Es muy posible que la concordancia entre dos métodos sea escasa simplemente porque uno de ellos tiene límites de concordancia amplios mientras que el otro los tiene estrechos. En este caso, el método con límites de concordancia estrechos sería superior desde el punto de vista estadístico, aunque consideraciones prácticas o de otro tipo podrían cambiar esta apreciación. Lo que constituye unos límites de acuerdo estrechos o amplios o un sesgo grande o pequeño es una cuestión de valoración práctica en cada caso.
Alfa de KrippendorffEditar
El alfa de Krippendorff es un estadístico versátil que evalúa el acuerdo alcanzado entre los observadores que categorizan, evalúan o miden un conjunto dado de objetos en términos de los valores de una variable. Generaliza varios coeficientes de acuerdo especializados aceptando cualquier número de observadores, siendo aplicable a niveles de medición nominales, ordinales, de intervalo y de razón, pudiendo manejar datos perdidos y corrigiendo para tamaños de muestra pequeños.
El alfa surgió en el análisis de contenido, donde las unidades textuales son categorizadas por codificadores entrenados, y se utiliza en la investigación de asesoramiento y encuestas, donde los expertos codifican los datos de las entrevistas abiertas en términos analizables, en la psicometría, donde los atributos individuales son probados por múltiples métodos, en los estudios de observación, donde los acontecimientos no estructurados se registran para su posterior análisis, y en la lingüística computacional, donde los textos son anotados por varias cualidades sintácticas y semánticas.